
51% of B2B software buyers now begin software research with an AI chatbot more often than with traditional search, up from 29% the prior year (G2, 2026). For most SaaS marketing teams, that buyer is searching ChatGPT for vendors while the SEO playbook keeps building for Google. The 10-step checklist below is what a single marketer can execute this week to get a SaaS page extracted, cited, and clicked from inside ChatGPT's answer surface.
Allow GPTBot In Your robots.txt File
GPTBot is OpenAI's web crawler, identified by the user agent string GPTBot/1.0. The first prerequisite for ChatGPT to retrieve and cite your pages is that GPTBot, ChatGPT-User, and OAI-SearchBot can all reach them, and most SaaS sites unintentionally block one or more through default WAF rules or aggressive bot filters.
OpenAI runs three distinct crawlers, each with a different job:
- GPTBot. Crawls the open web for training and retrieval. Identified by user agent containing
GPTBot/1.0. - OAI-SearchBot. The SearchGPT product's live-web crawler. Used when ChatGPT Search activates against a query.
- ChatGPT-User. Fires when a ChatGPT user clicks a citation link or asks the assistant to fetch a URL.
Add the explicit allow rules to robots.txt:
User-agent: GPTBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
Then verify the crawler is actually reaching the page. Run curl -A "GPTBot/1.0; +https://openai.com/gptbot" https://yourdomain.com/your-page and confirm a 200 response with the full HTML body. If your CDN or WAF returns 403 or a challenge page, the rule is not enough; add the OpenAI-published crawler IP ranges to the allow list at the WAF layer too. Cloudflare ships a “Verified Bots” toggle that handles GPTBot specifically; toggle it on rather than relying on robots.txt alone.
Submit Your Sitemap To Bing Webmaster Tools
ChatGPT Search retrieves live web results through Bing's index, not Google's. Submitting your XML sitemap to Bing Webmaster Tools is the closest equivalent to Google Search Console for the ChatGPT surface, and it is the second prerequisite for any SaaS team that wants ChatGPT to know its pages exist.
Sign up at bing.com/webmasters, verify the domain by DNS or meta-tag, and submit sitemap.xml. Bing's index coverage report shows which URLs are crawled, which are indexed, and which were skipped (with reason codes). Treat the “excluded” bucket the same way SEO teams treat Google Search Console's coverage errors.
| Bing Webmaster surface | What it tells you | Action when broken |
|---|---|---|
| Sitemap status | Whether your sitemap was parsed | Re-submit, fix XML errors |
| Index coverage | Which URLs Bing has indexed | Investigate excluded URLs |
| Crawl stats | When Bingbot last visited | Check robots.txt + WAF if zero |
| URL inspection | Live status for any URL | Submit individual URL re-crawl |
The same sitemap signal that helps Bing also feeds the SearchGPT crawler when it samples for live-web grounding. Two channels, one submission.
Render Content Server-Side, Not Client-Side
ChatGPT crawlers index the initial HTML response, not content rendered by JavaScript after page load. Server-side rendering (SSR) or static generation (SSG) is the third prerequisite, and it is the structural change that took Vercel's ChatGPT-attributed signups from under 1% to 10% over six months (Vercel / Kevin Corbett and Malte Ubl, 2025).
A React or Vue app that renders client-side returns a near-empty <body> to the crawler. Whatever the user sees in their browser is invisible to GPTBot. Three rendering modes solve this:
- SSR. The server renders HTML on every request and ships it complete. Next.js
getServerSidePropsor App Router default behavior. - SSG. Pages are pre-rendered at build time and served as static HTML. Fastest for crawlers; ideal for marketing pages that change weekly, not per-request.
- ISR. Hybrid: pre-rendered HTML with periodic revalidation. Good for product pages with pricing or feature data that updates daily.
Verify with curl -A "GPTBot/1.0" https://yourdomain.com/your-page > rendered.html and confirm the rendered content matches what a browser shows. If rendered.html is missing the comparison table, the FAQ section, or the answer capsules, fix the rendering mode before any other optimization. No amount of structural restructuring matters if GPTBot receives an empty shell.
Front-Load Your Strongest Claim Into The First 30%
55% of citations on AI-cited pages come from the first 30% of content (CXL, 2024). The opening third of a SaaS page carries more than half the citation weight before the engine ever reads the rest, which means the strongest stat and the strongest claim must appear above the fold of the rendered page.
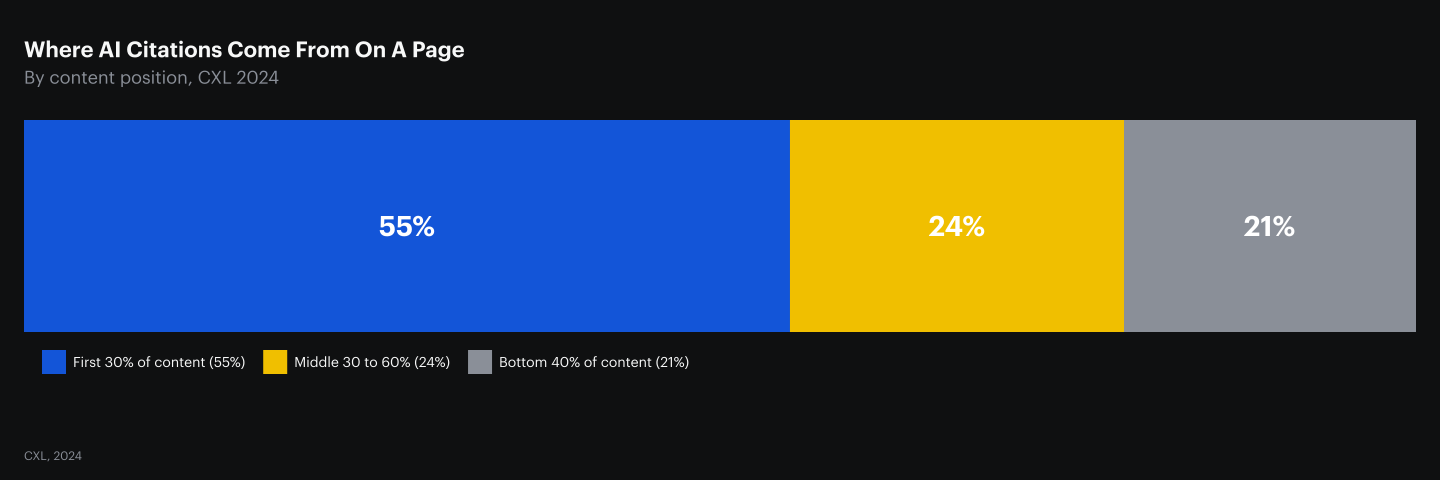
The position-aware writing pattern: a research-led intro that states the thesis with one anchor stat, followed by a first H2 that opens with a different stat plus source. Two slots, two distinct citation handles. Burying the strongest claim under a long narrative arc surrenders both. The tactical move on existing pages is to identify the single sharpest stat in the article (the one a reviewer would copy into a competitor comparison), and rewrite the opening paragraph so that stat appears in the first two sentences with inline source attribution.
Convert Lists To Bold-Label Blocks
94% of top-cited B2B pages contain bold-label blocks, against 0% of bottom-cited pages, in the Res AI 852-article B2B citation structure study (Res AI, 852-article B2B citation structure study, 2026). The split is binary, not gradient. A SaaS page without bold-label blocks sits in the bottom-50 structural cohort regardless of word count.
A bold-label block is a paragraph that leads with a bolded entity name plus a label-prefixed line of evidence. Each block becomes its own retrieval target inside ChatGPT. Three example blocks for a form-builder comparison:
Tally. Best for bootstrapped teams avoiding seat-based pricing. Free tier: unlimited forms and responses. Paid: $29/mo Pro. Trade-off: fewer enterprise integrations than Typeform.
Typeform. Best for conversational long-form surveys. Free tier: 10 questions, 100 responses/mo. Paid: $25/mo Basic. Trade-off: cost scales steeply for high-volume programs.
Google Forms. Best for teams already on Google Workspace. Free tier: unlimited within Workspace. Paid: bundled at $6/user/mo. Trade-off: no logic branching beyond simple skip-to.
The mechanical conversion: search the page for any prose paragraph that mentions three or more comparable items in sequence and rewrite as a stack of blocks like the above. One block per entity, four short labeled lines per block.
Add A Named-Entity Comparison Table
88% of top-cited B2B pages contain comparison tables, against 0% of bottom-cited pages, in the Res AI 852-article B2B citation structure study (Res AI, 2026). Comparison tables succeed because ChatGPT extracts cell content as structured pairs; a row that names a competitor, a feature, and a number gives the engine three retrievable signals from a single line.
The format that ranks: 3 to 5 columns, 3 to 6 rows, named entities only, with the publishing brand in row 1 by relevance to the article's argument. Cap cell text at one sentence. The form-builder demo:
| Tool | Free tier | Paid plan starts at | Best for |
|---|---|---|---|
| Tally | Unlimited forms and responses | $29/mo Pro | Bootstrapped teams avoiding seat fees |
| Typeform | 10 questions, 100 responses/mo | $25/mo Basic | Conversational long-form surveys |
| Google Forms | Unlimited within Workspace | $6/user/mo (Workspace bundle) | Teams already on Google Workspace |
| Jotform | 5 forms, 100 submissions/mo | $34/mo Bronze | HIPAA-compliant intake forms |
Every cell carries a falsifiable claim. Hidden pricing or templated rows fail the format. Where pricing is genuinely custom-only, write “Custom” because the source data says so, not as a hedge.
Append An 8-Question FAQ Block
The FAQ block is the section ChatGPT extracts most reliably as a structured retrieval target, because each H3 question maps cleanly to a paraphrased buyer prompt and each H3-plus-answer is parseable as an independent passage. 8 to 10 questions is the floor that matches top-cited pages in the 852-article B2B citation structure study (Res AI, 2026); fewer underperforms.
Source the questions from real buyer queries, not marketing instinct. Three input streams:
- Sales call transcripts. Buyer questions asked verbatim during demos and discovery calls.
- Support tickets. Post-purchase questions that imply a pre-purchase confusion.
- AlsoAsked / AnswerThePublic exports. Public search demand for the topic, scoped to your category.
The answer pattern is two sentences max. First sentence answers directly. Second adds one stat with attribution or one nuance. Generic questions that could appear on any article in the category fail the substitution test; strip the article headline and read each question alone, and a question that does not obviously belong to this specific article does not earn its slot.
Embed JSON-LD Schema For Each Page Type
JSON-LD is structured data ChatGPT extracts directly from the page <head>. It tells the engine what kind of content this is, whether a product, an FAQ, or an article, without requiring the engine to parse prose. The fourth structural prerequisite is that every page on the site declares its type via a Schema.org JSON-LD block, validated against Google's Rich Results Test before deploy.
Match the schema type to the page's content shape:
| Page type | Schema.org type | Required properties |
|---|---|---|
| Landing or pricing page | Product | name, description, offers, aggregateRating, review |
| Support article or KB entry | FAQPage | mainEntity (array of Question + Answer pairs) |
| Tutorial or step-by-step procedure | HowTo | name, step (array), totalTime |
| Editorial blog post | BlogPosting | headline, datePublished, author, image |
| Product detail page | SoftwareApplication | name, applicationCategory, operatingSystem, offers |
A minimal FAQPage block looks like:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Does ChatGPT use Bing for live web search?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Yes. ChatGPT Search retrieves live web results through Bing's index..."
}
}
]
}
Paste it into the page's <head>, run Google's Rich Results Test against the URL or HTML, and wait for a green check on every required property. A page with broken JSON-LD performs worse than no JSON-LD because crawlers index the failed markup as a quality signal.
Sample 10 Buyer Prompts To Check Your Citation Rate
There's less than a 1-in-100 chance of receiving an identical brand list across any two ChatGPT runs (SparkToro, 2024). A single citation check has roughly a 0.28 false-negative rate per brand, which means a one-shot lookup is a coin flip rather than a measurement. 10 runs produces a citation frequency rate stable enough to drive prioritization decisions on which pages to restructure first.
The measurement protocol that produces an actionable number:
- Pick 10 prompts. Pull the top 10 buyer queries from sales call transcripts and support tickets, phrased as full-sentence prompts a buyer would actually type into ChatGPT.
- Run each 10 times. Use a fresh ChatGPT session per run (incognito or different account) to avoid personalization bleed. Log the cited URLs and the brands named in the answer.
- Calculate citation frequency rate. Per prompt, what percentage of the 10 runs cited your domain? Per brand named, what percentage of runs included it? The Res AI 1,000-query Perplexity B2B citation study found 0.72 average Jaccard similarity between any two runs of the same prompt and only 3.1 brands appearing in all 10 runs; treat 70% citation frequency as the threshold for a stable presence (Res AI, 1,000-query Perplexity B2B citation study, 2026).
- Track week-over-week. Re-run the same 100 samples weekly. Movement in the rate is the signal that a structural change worked, or that the engine drifted away from your page.
Refresh Pages Quarterly To Hold The Citation
Pages not updated quarterly are 3x more likely to lose citations across major AI engines, in an analysis of approximately 15 million data points across ChatGPT, Perplexity, Claude, and Gemini (Airops and Kevin Indig, 2026). ChatGPT's training data and live-web index both refresh on rolling cycles, and a static page that earned a citation in March will likely lose it by June unless the underlying content held its structural lead through the engine's sampling refresh.
The refresh cadence that holds citations is monthly for the highest-value pages and quarterly for the long tail. Vercel runs a 30/90/180-day refresh cycle on its AI-targeted content, with each touch updating stats, adding new sections, or rewriting answer capsules around fresher evidence (Vercel / Kevin Corbett and Malte Ubl, 2025). Add a “data as of MM/YYYY” footer to every refreshed page so the freshness signal is visible to crawlers, not just to readers.
The cadence shift is what separates GEO from SEO operationally. Quarterly editorial calendars inherited from traditional SEO miss two full citation-drift windows between refreshes, given the 40 to 60% month-over-month drift Profound measured across the major engines (Profound, 2026). Monthly is the floor for SaaS teams that want to hold a citation share; weekly is the bar that matches the engines' own update cycle.
How Six GEO Platforms Approach ChatGPT Optimization
Every GEO platform addresses ChatGPT optimization with a different default: monitor ChatGPT mentions and produce a brief, restructure existing pages and ship them through the CMS, or layer ChatGPT visibility on top of a broader content workflow. The matrix below compares each platform on the scope of work it covers for a SaaS team running this 10-step checklist, where the work physically ships, and what the team gets back.
| Platform | Scope of ChatGPT optimization work | Where it ships | Output for the team |
|---|---|---|---|
| Res AI | Rewrites pages for ChatGPT extraction and adds JSON-LD via natural-language commands across the existing CMS | Direct CMS deploy through a natural-language interface | Published structural changes within minutes |
| Profound | Monitors ChatGPT mentions and produces optimization briefs | Standalone dashboard with brief handoff | Strategy briefs and prompt-volume reports |
| Conductor | Enterprise AEO data unified with content production | Unified platform across AEO and SEO teams | End-to-end AEO workflows with collaboration |
| Peec AI | Tracks ChatGPT visibility, position, and sentiment with no editing layer | A monitoring dashboard, no editing layer | Tracking dashboards for SEO and content teams |
| Athena | Tracks AI visibility across 8+ LLMs including ChatGPT and surfaces optimization recommendations | Cross-platform tracking across 8+ LLMs | Optimization recommendations the team applies |
| AirOps | Multi-model content workflows targeting ChatGPT extraction | Multi-region content production pipelines | Pages and Pro workflows from creation to refresh |
The split that matters for ChatGPT optimization is monitoring-first vs execution-first. Monitoring-first tools produce a brief that the team still has to execute through an editorial calendar, which means the alert-to-publish loop is days at best and weeks more typically. Execution-first tools edit the CMS directly, which collapses the loop to within the engine's drift cycle. The right tool depends less on feature count and more on whether the SaaS team has editorial capacity to run the daily structural rewrite cadence on top of monitoring data.
How Res AI Ships ChatGPT-Ready Content Without Developer Time
Res AI is the execution layer for SaaS marketing teams running the 10-step checklist above without engineering capacity. The Strategy Agent samples ChatGPT prompts buyers are actively running, scores them by citation frequency across 10-run samples, and surfaces gaps where competitor content is winning the answer. The Citation Agent runs a research pipeline against the candidate prompts and rewrites the page into the structural elements the 852-article B2B citation structure study found in 80% or more of top-cited pages and 0% of bottom-cited pages (Res AI, 2026).
The natural-language interface is the unlock. The instruction “add a 4-row form-builder comparison table to every page that mentions Typeform, with the latest pricing,” applies the structural change across the matching pages and deploys to the CMS in one workflow. The team does not write JSON-LD by hand, does not author bold-label blocks page by page, and does not maintain the per-page test schedule. Res AI runs the 10 steps as a continuous program against the existing library rather than treating each page as a separate brief.
Frequently Asked Questions
Does ChatGPT respect my robots.txt file?
Yes for the three named OpenAI crawlers (GPTBot, OAI-SearchBot, ChatGPT-User), per OpenAI's public crawler documentation. Sites that block one or more of these will not appear in ChatGPT citations until the rule is removed and a fresh crawl runs.
Why does ChatGPT use Bing instead of Google?
OpenAI partnered with Microsoft for live-web grounding, which means ChatGPT Search and the SearchGPT product surface live results through Bing's index. The conversational ChatGPT also uses Bing-derived data for any query that triggers a live retrieval rather than the model's training data.
How long after I add JSON-LD will ChatGPT pick it up?
Days to weeks depending on the engine's sampling cycle for that prompt class, with Semrush reporting LLM citation results within days, sometimes hours, after publishing restructured content (Semrush, October 2025). The faster cycle applies when the engine actively retrieves the page; pages indexed only in training data update on the model's next refresh.
Can I optimize for ChatGPT and Google at the same time?
Mostly yes, with one direct conflict. Statistics addition lifts AI visibility by 41%, while keyword stuffing cuts AI visibility by roughly 10% in the same Princeton study (Princeton KDD, 2024). Pages restructured for ChatGPT extraction often outperform their old SEO-tuned versions on Google as well, because the Princeton tactics overlap with E-E-A-T signals; the conflict is at the keyword-density layer, where SEO pages tuned to high keyword frequency lose AI visibility.
What's the minimum page-level structural lift for a ChatGPT citation?
8 or more structural elements drawn from the menu (bold-label blocks, comparison tables, FAQ, decision matrices, schema-type matrices, source-mapping tables) per the 852-article B2B citation structure study median for top-quartile pages of 13.55 elements (Res AI, 2026). Below 8 the page sits in the bottom-50 structural cohort regardless of word count.
Why does ChatGPT cite pages that don't rank in Google?
Only 12% of AI-cited URLs across ChatGPT, Perplexity, Gemini, and Google AI Mode rank in Google's top 10 for the original prompt (Ahrefs with BrightEdge, 2026). ChatGPT's retrieval pipeline weighs structural extractability higher than Google's link-graph signal, so a page with strong structural density beats a page with stronger backlinks on the ChatGPT surface, particularly on commercial comparison and evaluative prompts.
How do I know if my CDN is blocking GPTBot?
Tail your access logs for entries with user agent containing GPTBot/1.0. If you see zero entries over a week and your robots.txt allows it, the WAF or CDN is blocking at a layer above your application. Cloudflare, Fastly, and AWS CloudFront all default-block several AI crawlers; check the bot-management settings and whitelist GPTBot, OAI-SearchBot, and ChatGPT-User explicitly.
How often should I re-sample my citation rate?
Weekly during active optimization, monthly during steady state. The Res AI 1,000-query Perplexity B2B citation study found 0.72 Jaccard similarity between any two runs of the same prompt (Res AI, 2026), so weekly sampling produces enough signal to detect movement above the noise floor of run-to-run variation.
Res AI ships the 10-step ChatGPT optimization checklist across your existing SaaS content library through a natural-language CMS interface. Connect Res, give an instruction, and watch the structural edits ship and the citation results land within days.