
ChatGPT and Perplexity together account for 90.4% of all AI referral traffic to B2B SaaS websites (PipeRocket Digital, 2025). For most B2B marketing teams, the practical question is which of the two to optimize for first. The right answer is Perplexity, and the case has three independent layers: a structurally protected citation surface, a higher structural bar that wins both engines at once, and an audience composition skewed to higher-authority B2B buyers.
Perplexity Said Ads Make Users Doubt Every Answer
Perplexity wound down its sponsored answer program through 2025 and fully exited the ad market by early 2026, with a company executive telling PYMNTS that “a user would just start doubting everything” if ads continued (PYMNTS, 2026). The company launched its sponsored answer program in November 2024 (TechCrunch, 2024) and quietly retreated after about a year. The official rationale was structural, not tactical: an AI search engine that injects sponsored content into its answers compromises the trust that makes users pay for and return to the product.
ChatGPT moved in the opposite direction in 2026. OpenAI launched its first ad placements at $60 CPM with a $200,000 minimum commitment for the beta program (CNBC, 2026). The Res AI coverage of the launch walks through the placement formats and timeline in detail.
The contrast is the cleanest version of a strategic split forming since 2024. Perplexity is monetizing through subscriptions and enterprise contracts, having reached $100M ARR by end of 2025 (demand-sage, 2026). OpenAI is monetizing through advertising at projected $30 billion in revenue by 2030 (CNBC, 2026). For content teams optimizing for AI citation, this is not a neutral business decision. It is a fork in what each engine will reward over the next 24 months.
Perplexity is not alone in choosing trust over advertising. Anthropic has publicly committed to keeping Claude ad-free, building its business on enterprise contracts and consumer subscriptions instead (PYMNTS, 2026). The split inside the AI search market is now clean enough to predict. The engines that monetize through subscriptions will keep their citation surfaces aligned with answer quality. The engines that monetize through advertising will not.
Stable Engines Reward Long-Term Optimization. ChatGPT Does Not.
When Gemini 3 rolled out in January 2026, 42% of previously cited domains lost their citations in a single model update (SE Ranking, 2026). Any AI engine that updates aggressively, especially under pressure from a growing ad business, resets the optimization work content teams put into it. Perplexity is the only major AI search engine that has explicitly committed to a monetization model that does not require this kind of churn.
The implication for teams setting up GEO workflows is structural. If you optimize for an engine that gets retrained, reranked, and restructured around new ad placements every six months, you are betting your investment against a moving target. The structural anatomy that worked in Q1 might be the anatomy the engine deprioritizes in Q3 because it conflicts with a new ad format.
The Perplexity executive quote on ads is not just a brand promise. It is a structural commitment to keep selection criteria aligned with answer quality, not advertiser preference.
The pattern of monetization-driven compression is already visible elsewhere. Google’s organic search surface has been progressively compressed since paid ads moved above the fold, with brand bidding, shopping ads, and now AI Overviews each taking another slice of the result page. Every content team that built equity on the old organic surface has had to rebuild it multiple times. ChatGPT is at the start of that same trajectory. Perplexity has opted out.
On a stable engine, every well-structured article you publish keeps earning citations as long as the underlying retrieval system stays consistent. On an unstable engine, the same article needs to be re-optimized every time the model gets retrained against new monetization objectives.
The math compounds in favor of the team that picked the stable target.
Only 11% of Cited Domains Overlap Between ChatGPT and Perplexity
Averi’s 2026 analysis of 680 million citations found that only 11% of cited domains appear in both ChatGPT and Perplexity (Averi, 2026). The two engines pull from substantially different content libraries, with very little overlap even on identical query intent.
Source preferences diverge sharply on the highest-volume sources:
| Engine | Top Source Type | Top Source Share |
|---|---|---|
| ChatGPT | Wikipedia | 47.9% |
| Perplexity | 46.7% | |
| Google AI Overviews | YouTube | 23.3% |
Source preferences this far apart are not stylistic. They reflect different selection algorithms, different recency weights, and different definitions of “authoritative.” A B2B SaaS team that wins citation on ChatGPT through a structurally complete vendor blog might not win on Perplexity at all if Perplexity’s preference is for community-validated discussion. The reverse also applies: pages that dominate Reddit-style structured discussion may be invisible to ChatGPT’s Wikipedia-leaning retrieval.
The Reddit dependency is significant for B2B vendors. Perplexity treats threaded community discussion as a primary authority signal on commercial topics, which means a B2B SaaS team that wants to win citation on Perplexity needs an active Reddit presence in addition to a structurally complete vendor blog. The same vendor optimizing only for ChatGPT can rely on a Wikipedia-leaning content strategy: well-structured articles, named entities, consistent attribution. Different surfaces, different sourcing strategies, almost zero overlap in the content investment required.
The structural proof is in the lack of overlap. AI search optimization is not a single discipline. It is at least two.
Perplexity Returns 26% More Structured Pages Than ChatGPT
Pages cited by Perplexity have a mean structural total 26% higher than pages cited by ChatGPT, according to the Res AI 852-article B2B citation structure study (Res AI, 2026). Perplexity is the stricter engine. Its citation surface rewards structural completeness more reliably than ChatGPT’s.
The absolute numbers were 7.52 structural features per page on Perplexity sonar-pro and 6.25 on ChatGPT gpt-4o-search-preview. The corpus measured 11 deterministic features per article including comparison tables, FAQ sections, how-to-choose frameworks, and product reviews.
The composition of returned pages also diverges. Perplexity skews toward listicles and comparisons. ChatGPT spreads more thinly across opinion essays and edge cases including vendor product pages and academic journals.
A listicle with full structural anatomy (table, product reviews, how-to-choose, FAQ) will be picked up by both engines because it satisfies Perplexity’s strictness and clears ChatGPT’s broader range. The reverse path is harder: an opinion essay that wins on ChatGPT rarely satisfies Perplexity’s structural requirements at all. The composition data and the structural data are pointing at the same optimization target.
| Article Type Returned | Perplexity Share | ChatGPT Share |
|---|---|---|
| Listicle | 30% | 27% |
| Opinion essay | 42% | 40% |
| Comparison | 19% | 20% |
| Other (product, edge cases) | 9% | 13% |
The combined picture: Perplexity expects more structure, accepts a narrower range of article types, and rewards pages that come closer to a canonical “top N for X” template. ChatGPT is more permissive on both structural completeness and type variety, which means a page built to ChatGPT’s bar may be missing the structural anatomy Perplexity demands.
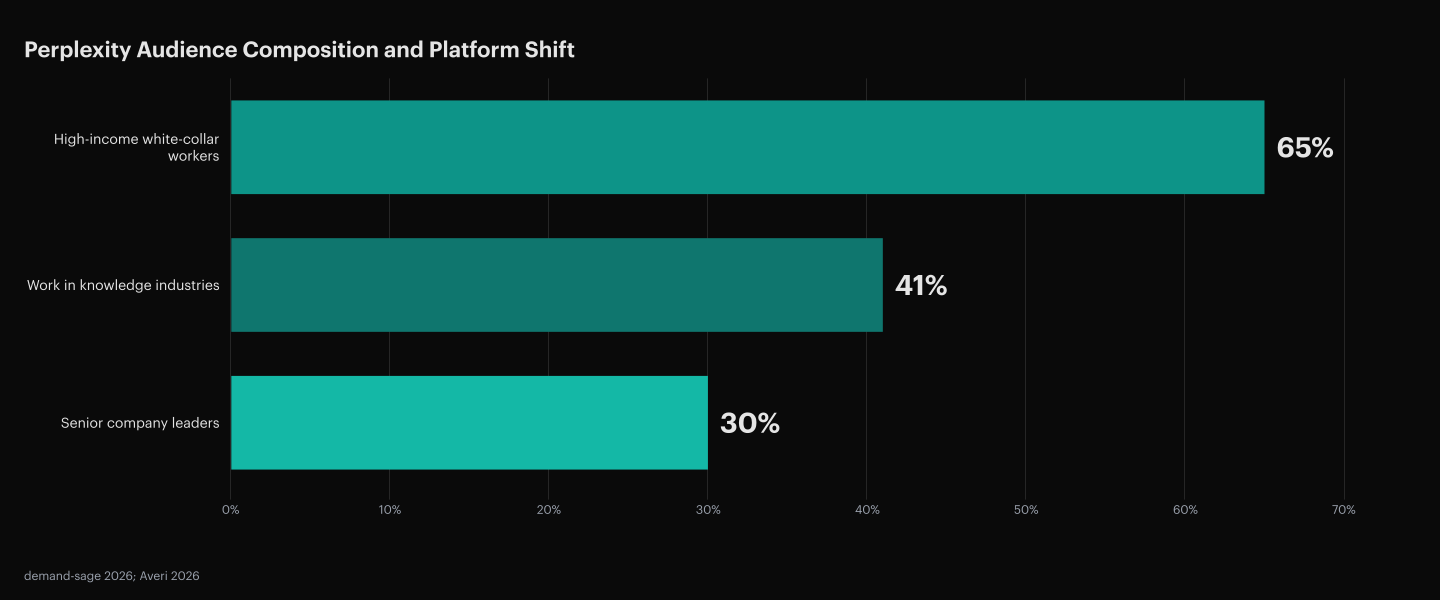
Perplexity’s Audience Is 30% Senior Company Leaders
30% of Perplexity users are senior company leaders, the highest share of senior decision-makers among any major AI search engine (demand-sage, 2026). The audience composition is closer to a B2B buyer panel than to a consumer search engine.
Most search surfaces span the full spectrum of intent and authority, from casual readers to qualified buyers. Perplexity’s audience is skewed toward the buyer end of that spectrum by default. For B2B SaaS teams targeting Series A through C buyers, this is the ICP composition that makes each Perplexity citation more valuable than the per-click numbers suggest.
65% of the user base is high-income white-collar workers, and 41% work in knowledge industries like technology and finance (demand-sage, 2026). Desktop usage tells the same story from a different angle. Perplexity’s desktop share grew from 36.5% in February 2024 to 83.5% in March 2025, the trajectory of a product moving from mobile-first consumer chat to professional research surface.
The honest counter-data point is per-click conversion. Loganix’s 2026 cross-engine analysis put Perplexity referral conversion at 12.4% versus ChatGPT at 14.2% (Exposure Ninja / Loganix, 2026). On the surface, ChatGPT looks like the better channel.
The discrepancy resolves once you measure session depth. Perplexity referrals average 9 minutes on the destination site and 13 pages per visit (Averi, 2026). The same comparison window puts Google referrals at 8.1 minutes and 11.8 pages.
Perplexity sends fewer but better clicks to a more engaged, higher-authority audience. For B2B SaaS pipelines where one closed deal is worth $50,000 to $250,000 ARR, audience composition matters more than per-click marginal conversion. A single Perplexity-driven deal at average B2B SaaS ACV offsets the per-click conversion gap across thousands of ChatGPT visits.
Optimize for Perplexity First. ChatGPT Follows Automatically.
Articles meeting Perplexity’s structural bar also clear ChatGPT’s lower bar, but pages built only to ChatGPT’s threshold often miss Perplexity’s, since Perplexity returns 26% more structured pages on average (Res AI, 2026). The strict-engine-first tactic gets you both engines for the price of one optimization target.
The volume counter-argument is real but secondary. ChatGPT accounts for around 78% of total AI referral traffic, with Perplexity at around 7% (Averi, 2026). For consumer-facing publishers chasing total session count, that gap matters. For B2B SaaS teams measuring qualified pipeline rather than session volume, it does not. Perplexity’s smaller traffic share arrives from buyers with higher purchase authority and deeper session engagement, and the strict-engine-first tactic captures the larger ChatGPT audience as a side effect.
The 12-month picture compounds the case. ChatGPT’s ad business will keep expanding, the placement formats will evolve, and the organic citation surface will keep getting compressed in the same way Google’s organic surface got compressed when AdWords moved above the fold. Perplexity has explicitly opted out of that trajectory. Teams that pick the strict, stable, higher-intent engine as their primary target build optimization equity that compounds. Teams that chase ChatGPT volume rebuild from scratch every time the ad system reshuffles the citation surface.
The compounding works in two directions. On Perplexity, every well-structured article published in 2026 has a high probability of still earning citations in 2028 because the selection criteria are anchored to answer quality. On ChatGPT, the same article will need to be rewritten or restructured each time the underlying model is retrained against new monetization objectives. The optimization equity stays positive on the stable engine and resets on the unstable one.
How to Choose Your Primary AI Search Target
The strict-engine-first tactic does not automatically make Perplexity the right target for every team. Use these decision rules in order to confirm or override the default.
If your ICP is B2B SaaS buyers in tech or finance, default to Perplexity first. The audience skew (30% senior leaders, 41% in knowledge industries, 65% high-income white-collar) matches the decision makers your sales team is trying to reach. The lower per-click volume is offset by the higher audience authority per click.
If your ICP is consumer or prosumer, invert the default and optimize for ChatGPT first. Perplexity’s audience is too narrow for categories where buying authority is distributed across a broader demographic. For those teams, ChatGPT’s 78% traffic share is the dominant signal.
If you have the resources to optimize for only one engine, pick the strictest one in your target set. For most B2B teams this is Perplexity because its structural bar is measurably higher (26% more structured pages cited on average). Meeting the stricter bar produces articles that also clear the looser bar, so the investment captures both engines at the cost of one.
If you have the resources to optimize for multiple engines in parallel, add Claude next. Anthropic has committed to keeping Claude ad-free (PYMNTS, 2026), so it shares Perplexity’s stability profile. Adding Claude after Perplexity doubles your stable-engine coverage without adding volatility.
If stability matters more than audience composition, Perplexity is still the answer. An engine that reshuffles 42% of cited domains on a single model update (SE Ranking, 2026, on Gemini 3) is an engine where every optimization investment is perishable. Perplexity’s explicit commitment to answer quality over monetization means your work compounds instead of resets.
The output is a primary engine and, optionally, a secondary engine to add once the primary is producing citations. Do not try to optimize for four engines at once from the start.
Frequently Asked Questions
Why does Perplexity’s Reddit preference produce different B2B winners than ChatGPT’s Wikipedia preference?
Wikipedia rewards named entities, editorial authority, and citation density between established references. Reddit rewards authentic user discussion, specific examples, and threaded depth on a single topic. A B2B vendor wins on Wikipedia by being mentioned in named-entity roundups and industry references, while a vendor wins on Reddit by being discussed in threads where actual users describe real use cases. The two authority signals are measuring different things, which is why the same brand rarely dominates both engines.
How should you measure whether Perplexity optimization is actually working?
Perplexity does not send enough referral traffic to show up cleanly in standard analytics, so traditional SEO metrics are misleading. The measurable unit is citation frequency: how often your brand appears in Perplexity’s answer for the buyer queries that drive your pipeline. Track it by running the target queries yourself across Perplexity on a weekly cadence and recording whose content gets cited.
Can an article optimized for Perplexity today still earn citations after a model update in 6 months?
Perplexity has not made public commitments about update frequency, so some turnover is expected on any engine. The stability advantage is relative: Perplexity’s subscription monetization does not create pressure to retrain against new ad placements. Articles optimized around structural completeness (attributed stats, comparison tables, clear entity mapping) tend to survive model updates because they satisfy the underlying retrieval objective regardless of tuning.
Why does OpenAI think ads are fine for ChatGPT if the trust argument against ads is so clear?
OpenAI is funding massive compute costs and needs scaled revenue faster than subscriptions alone can provide. ChatGPT processes around 2.5 billion prompts per day globally, of which roughly 330 million come from U.S. users (OpenAI via Axios / TechCrunch, 2025). At that query volume, ad inventory rivals Google Search for reach, which makes the financial case for ads strong enough to override the product-trust case, especially given the $30 billion projected ad revenue by 2030 (CNBC, 2026).
How do you optimize a single article for Perplexity and ChatGPT at once when their source preferences are so different?
You cannot optimize the source ecosystem with a single article, but you can build the structural anatomy both engines reward. Structural completeness (comparison tables, attributed stats, product reviews, how-to-choose frameworks) travels across both engines because both retrieval systems extract the same kinds of passages. Source diversity (Reddit presence for Perplexity, industry reference coverage for ChatGPT) is a separate, longer-term investment that runs in parallel to article-level work.
What happens to your Perplexity citations if Perplexity eventually reverses its ad decision?
The stability argument weakens if Perplexity reintroduces ads, but the structural argument holds regardless. Articles built to Perplexity’s current strict bar satisfy any retrieval system that prioritizes extractable anatomy over keyword matching. Even under a hypothetical ad-funded future Perplexity, structurally complete pages would still be preferred over unstructured ones, because the retrieval pipeline is designed around extraction and not around ad inventory.
Why does ChatGPT still win for developer-tool and SMB categories even with Perplexity’s higher structural bar?
The structural bar is real, but audience composition eventually overrides it when the buyer persona does not match Perplexity’s senior-leader skew. Developer tools, consumer SaaS, and SMB software have buying committees that skew younger and more tactical, which matches ChatGPT’s broader audience. In those categories, ChatGPT’s larger absolute volume reaches more real buyers than Perplexity’s stricter bar captures. The Perplexity-first default applies specifically to B2B categories with senior-leader buyers (enterprise software, security, finance infrastructure); outside those, the audience argument inverts.
How does Claude fit into a Perplexity-first optimization strategy given it’s also ad-free?
Claude’s referral traffic converts at 16.8%, the highest per-click rate of the major AI engines (Exposure Ninja / Loganix, 2026), and Anthropic has publicly committed to keeping Claude ad-free. That makes Claude the natural second stop after Perplexity: same stability profile, same trust-first monetization, highest per-click conversion. Articles built to Perplexity’s structural bar transfer to Claude with minimal additional work because both engines reward the same structural signals.
Does Perplexity’s subscription revenue actually support long-term independence from ads?
Perplexity reached $100 million ARR by end of 2025, most of it from Pro subscriptions at $20 per month and enterprise contracts (demand-sage, 2026). The math is not yet at the scale of OpenAI’s projected ad revenue, but it is a real, growing business that does not require ads to survive. Whether it supports long-term independence depends on how fast subscription revenue compounds against compute costs, which is the key variable worth watching over the next 18 months.
How Res AI Hits the Perplexity Bar Daily Across 4 Engines
The strict-engine-first tactic this article describes is the operational shape of Res AI. Instead of writing for the lowest common denominator, Res AI drafts every article against the structural requirements that win on Perplexity (full comparison table, how-to-choose framework, bold product blocks, pricing grid, product reviews, and definitions at the 3,500-word floor) so the same article also clears ChatGPT’s lower bar without separate rework.
Citation monitoring runs daily across ChatGPT, Perplexity, Gemini, and AI Overviews. When the daily scan shows a competitor is cited where you are not, Res AI surfaces the structural gap that explains the difference, drafts the missing structure, and publishes directly into WordPress, Webflow, Framer, or Contentful. The cadence is daily because the citation pool changes faster than a weekly editorial cycle can match.
The Perplexity bar is the optimization target because it is the strictest, the most stable, and the audience is the most research-oriented. Optimizing for the strictest bar is the only way to capture both engines without rebuilding the work each time the underlying model gets retrained.
Res AI monitors ChatGPT, Perplexity, Gemini, and AI Overviews every day to find the buyer queries where competitors are cited and you are not. It drafts the structurally complete content needed to win the Perplexity bar (which also clears the ChatGPT bar) and publishes directly to your CMS at the cadence AI engines reward.