
Most GEO teams evaluate a piece of content by running the target prompt once and screenshotting the result. There is less than a 1-in-100 chance that any two runs of the same prompt on ChatGPT return the identical brand list (SparkToro, 2024). The content that looks like it is failing by the screenshot is usually sampling the wrong tail of a distribution the team has not yet measured.
Non-Determinism Is The Default In AI Citation Output
Jaccard similarity between any two runs of the same prompt on Perplexity averages 0.72 across 1,000 B2B queries (Res AI, 1,000-query Perplexity B2B citation study, 2026). That means roughly 28% of the brand set rotates between two back-to-back runs of the same question even when the underlying content, index, and prompt are held constant. The variance is not a model glitch. It is the expected output shape of a retrieval pipeline that samples from a probability distribution at inference time.
The retrieval layer ranks a pool of candidate passages, and the generation layer selects from that pool with temperature and top-k sampling. The same query can pull chunks from different positions in the vector index between runs, and the model can pick a different subset of those chunks to quote. The citation output is a sample from a distribution, not a deterministic lookup. Treating the first sample as the population average is the measurement error at the root of most GEO reporting.
The practical consequence is that a team running the target prompt once and seeing its brand absent has not measured its citation performance. It has sampled one draw from a distribution with an expected run-to-run overlap of 72%. That distribution can only be characterized with multiple draws.
Three Brands Anchor Every Run; The Rest Rotate Through The Tail
Only 3.1 brands on average appear in all 10 runs of a given B2B query, while 8.2 unique brands surface across the 10-run set (Res AI, 1,000-query Perplexity B2B citation study, 2026). The citation surface for a typical prompt is roughly three deterministic slots and five rotating ones. A single run sees 5.4 brands on average, which is about 66% of the full surface.
The rotating positions are where most brands sit. If a brand is one of the five rotating mentions, it has a probability of appearing in any single run that is materially lower than 100%, and the screenshot check will miss it some percentage of the time even when the underlying citation frequency is healthy. Declaring that brand "not cited" after one run is a false negative generated by the measurement method, not by the content.
| Citation position type | Brands per query | Probability of appearing in any single run |
|---|---|---|
| Anchor positions | 3.1 | ~100% |
| Rotating positions | 5.1 | 20% to 80% |
| Single-run visible subset | 5.4 | per-run snapshot |
| Full 10-run citation surface | 8.2 | complete view |
The table shows why the sample size matters. A brand sitting in the rotating tier can register zero citations in a single-run audit and still be mentioned in 4 of 10 runs. The team needs to distinguish between "not cited" and "cited at 40% frequency" because the remediation plans are opposite. The first requires structural repair of the page; the second requires moving the brand up the retrieval ranking so the frequency lifts toward anchor territory.
Monthly Citation Drift Runs 40 To 60 Percent Without Model Updates
40% to 60% of the domains cited in one month drop out of citations the next month across ChatGPT, Perplexity, Gemini, Copilot, and Google AI Overviews even when the prompt and content are unchanged (Profound, 2026). Over six months the drift compounds to 70% to 90%. Non-determinism is not just a per-run phenomenon. The same prompt shifts its citation surface over time even between runs on the same model version.
The driver is index rotation and ranking updates inside the retrieval layer. The model pulls from a search corpus that changes daily, and the ranker reweights candidates as new content enters the index. A page cited in June might rank behind three newer pages in July and get displaced. A team that measured citation frequency in June and reads the same check in July is not looking at content performance. It is looking at ranker drift overlaid on content performance, with no way to separate the two signals.
This is what breaks quarterly reporting cadence on GEO programs. The quarterly comparison shows a citation decline, the team attributes it to the content, and the remediation cycle starts. The decline is often structural drift that would correct on the next ranker update. Without a measurement floor above monthly drift, the team is chasing noise as signal.
Model Updates Can Displace 42 Percent Of Cited Domains Overnight
42.4% of previously cited domains disappeared from Google AI Overviews after the Gemini 3 model update in January 2026, replaced by 46,182 new domains (SE Ranking, 2026). The average number of sources per overview grew 31.8% in the same window, from 11.55 to 15.22. Single-run measurement taken before and after a model update are measurements of two different retrieval systems and should not be directly compared as content performance data.
The displacement was concentrated in the long tail. The top 500 domains remained stable with only one dropping, but the mid-tail and long-tail citation surfaces rotated by more than 40%. A team whose citation frequency lived in the mid-tail saw its measured performance collapse overnight through no change in content. A team that did not timestamp its measurements against model version cannot reconstruct whether the January drop was content failure or model displacement.
The only defense is keeping measurement frequency higher than model update frequency. Gemini 3 shipped in January 2026, Sonnet 4.6 and 4.7 shipped in the preceding months, and GPT model updates rolled monthly. A quarterly citation check cannot survive these cadences. The measurement window has to close before the next model event, or the data is stale on arrival.
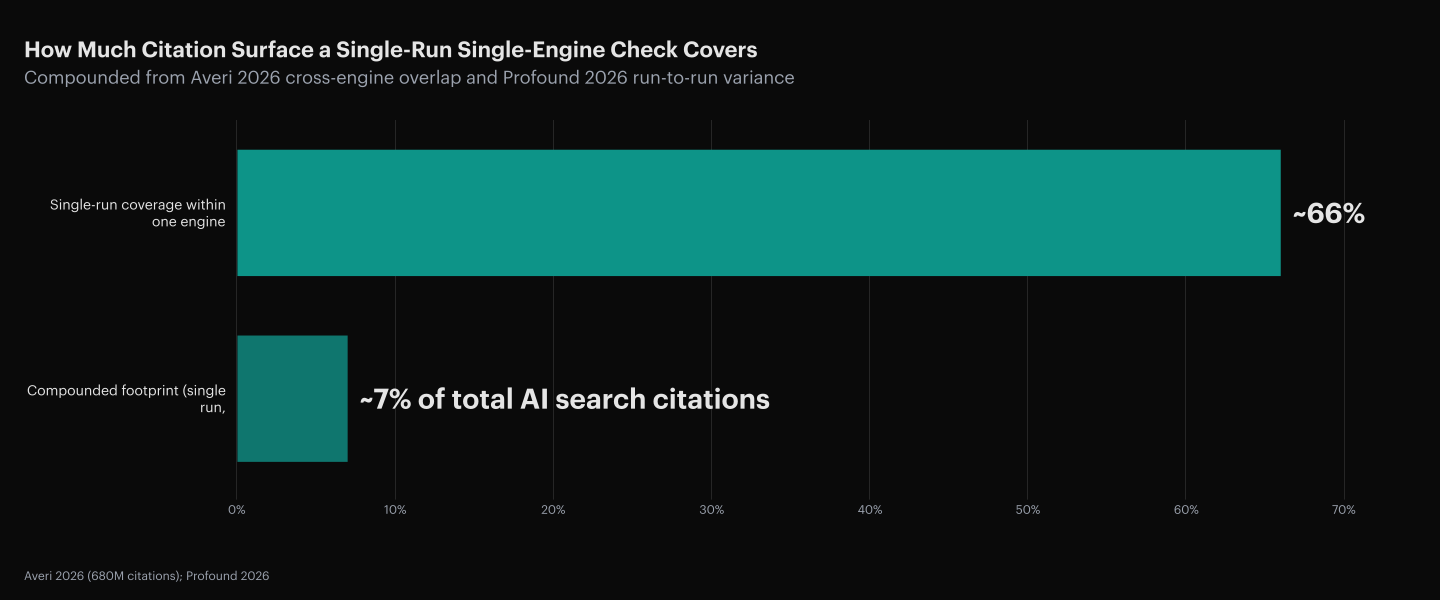
Cross-Engine Overlap Is 11 Percent So Measurement Must Multiply
Only 11% of cited domains appear in both ChatGPT and Perplexity results for equivalent prompts, across 680 million analyzed citations (Averi, 2026). A single-engine check measures 11% of the surface a buyer might encounter when they ask the same question in a different tool. 89% of citation performance lives outside the measurement frame of any one-engine audit.
| Engine pair | Citation overlap | Implication |
|---|---|---|
| ChatGPT ↔ Perplexity | 11% | 89% of citations are engine-specific |
| ChatGPT ↔ Gemini | not measured | treat as independent surface |
| Perplexity ↔ Gemini | not measured | treat as independent surface |
Gemini and ChatGPT now send roughly equivalent AI referral traffic to websites, with Gemini overtaking Perplexity as a referral source in January 2026 (SE Ranking, 2026). Buyers are not using one engine. They are querying two or three over the course of a shortlist build. A GEO measurement frame that checks ChatGPT once and reports back has an 89% blind spot per engine pair and a single-run sampling error on top of the engine blind spot.
The math compounds. A single-run, single-engine check sees roughly 66% of the citation surface on the engine it checked, and the engine it checked is 11% of the broader AI search surface. The effective visibility of a single check is the product of the two, well under 10% of the true citation footprint. Declaring content performance based on that sample is declaring it on a 7% sample.
How GEO Monitoring Tools Handle Non-Determinism
Every platform in this category now acknowledges non-determinism; they diverge on the engines they cover and on whether the measurement leads to execution or to another brief. The matrix below compares what each tool measures, how broadly it covers the engine landscape, and what follows the measurement.
| Platform | What it measures | Engine coverage | What follows the measurement |
|---|---|---|---|
| Res AI | Where competitors win the prompts your buyers run, and how your brand surfaces | ChatGPT, Perplexity, Claude, Gemini | Direct CMS edits via natural-language commands |
| Profound | Real-time brand presence across AI answer engines with prompt-volume context | 5 engines including AI Overviews | Strategy briefs the team or agency executes |
| Conductor | AI visibility unified with traditional Google rankings | ChatGPT, Gemini, Copilot, Claude, plus Google | Enterprise AEO + SEO workflows |
| Peec AI | Visibility, position, and sentiment scoring | Multi-model selection across the major LLMs | Tracking dashboards, no execution layer |
| Athena | AI visibility with citation source analysis | 8+ LLMs including Copilot and Grok | Optimization recommendations the team applies |
| AirOps | AI search visibility inside a content production pipeline | Multiple AI models | Content workflows from creation to refresh |
Execution after measurement is the differentiating column. Monitoring platforms end their output at a brief or a dashboard, and the team then has to route the brief to an agency or an internal writer to actually restructure the page. The time between "this content is drifting" and "the restructured page is live" is where the next model update lands, and the measurement that triggered the fix becomes stale before the fix ships. Pairing 10-run measurement with natural-language CMS execution closes the gap that drift windows open.
Frequently Asked Questions
Why does the same prompt return different brands in different runs?
Retrieval pulls from a ranked candidate pool and generation samples from that pool with temperature and top-k, so the same query can pull different chunks and quote a different subset. Run-to-run overlap on Perplexity averages 0.72 Jaccard similarity (Res AI, 1,000-query Perplexity B2B citation study, 2026).
How many runs are enough to call a measurement reliable?
Ten runs per prompt is the floor most studies converge on because it surfaces roughly 8.2 unique brands per query and separates the 3.1 anchor positions from the rotating tail. Below that threshold the single-run sampling noise dominates the content signal.
What is citation frequency and why is it the right unit?
Citation frequency is the rate at which a brand appears across N runs of the same prompt, expressed as a percentage. It converts a binary "was I cited" into a continuous measurement that can be tracked over time. Anchor citations register at 100%; rotating citations at 20% to 80% (Res AI, 1,000-query Perplexity B2B citation study, 2026).
How do model updates distort historical comparisons?
A model update can rotate 42.4% of the cited domain set in a single overnight change (SE Ranking, 2026). Before-and-after comparisons across a model version boundary are comparing two different retrieval systems, not two points on the same performance curve. Timestamp measurements against the model version in effect.
Can monthly reporting cadence work for GEO?
Monthly cadence is below the 40% to 60% monthly drift rate (Profound, 2026), so a monthly delta can be pure drift. Weekly or even per-update reporting is closer to the minimum, because the sampling window has to close before the next ranker change rotates the surface.
Why check more than one engine when ChatGPT has the largest share?
Only 11% of cited domains overlap between ChatGPT and Perplexity (Averi, 2026), and Gemini overtook Perplexity as a referral source in January 2026 (SE Ranking, 2026). A single-engine audit misses 89% of the surface per engine pair. Buyers query two or three engines over a shortlist build.
What is a false negative in single-run GEO measurement?
A false negative is a brand with healthy citation frequency that happens not to appear in the single run a team audited. Across 10 runs, the full citation surface contains 8.2 brands on average; a single run sees 5.4, leaving about 2.8 brands invisible per sample (Res AI, 1,000-query Perplexity B2B citation study, 2026).
How should drift be separated from content failure in reporting?
Maintain a control set of prompts whose target content has not been edited, and use the control drift as the baseline. If the measured drop on edited content does not exceed control drift, the decline is ranker rotation, not content failure. See why your AI visibility score is lying to you for the broader measurement design.
How does this affect execution-first vs monitoring-first GEO tools?
Monitoring tools that stop at a brief hand the team a measurement and a gap between brief and edit where the next model update lands. Execution-first GEO platforms close that gap by running the edit against the connected CMS, so the measurement that triggered the change is still current when the change ships.
How Res AI Runs 10-Run Citation Frequency Against A Connected CMS
The measurement problem and the execution problem are the same problem. A team that waits on a brief between run 10 of the audit and the CMS edit will see the next model update land inside that window and invalidate the measurement. Res AI runs 10-run citation frequency measurement across ChatGPT, Perplexity, Gemini, and Google AI Overviews, and then executes the structural edit directly against the connected CMS through a natural-language interface. The measurement and the edit live in the same surface, so the drift window never opens between them.
The Strategy Agent runs the tracked prompts at the cadence needed to clear monthly ranker drift and flags which brand positions are anchor versus rotating. The Content Agent then restructures the pages on the losing side of rotation directly inside WordPress, Webflow, Framer, or Contentful, without routing through an agency or a developer queue. A prompt like "add a comparison table with bold entity names to every article tagged CRM" stages a per-article diff for editorial approval and publishes on command. Res AI’s pricing is custom, scoped to each client’s library size, publishing cadence, and budget, with no fixed tiers and no per-plan prompt or page caps, so the coverage matches a full mid-library measurement-and-fix cycle inside a single model-update window.
The net effect is that citation frequency becomes a continuous metric the team can read weekly rather than a screenshot they argue over quarterly, and the remediation lands in the same week the measurement does.
Res AI tracks citation frequency across 10 runs per prompt and four engines, then executes the structural edit directly against the connected CMS through a natural-language interface. The measurement and the remediation ship inside the same model-update window so single-run sampling noise never reaches the dashboard.