Agentic Web Traffic Grew 7,851% in 2025 and Content Was Not Built for Agents
Autonomous agents drove 79x more web traffic in 2025 than overall AI growth, but most commercial content is still written for human session patterns.
 machina sculpsit · homo probavit · MMXXVI
machina sculpsit · homo probavit · MMXXVI94% of business buyers now use AI somewhere in the buying process, up five percentage points year over year (Forrester, 2025). The traffic those buyers and their delegated agents generate is no longer reading the web the way the content on it was written.
Agentic Web Traffic Grew 7,851% Year Over Year in 2025
Autonomous-agent web traffic grew 7,851% year over year in 2025 (HUMAN Security, 2026). Most commercial content on the receiving end of that traffic was written for human session patterns and is now being parsed by software that does not scroll, dwell, or recover ambiguous wording the way a human reader would.
That 79x agentic rise compounds against a 187% increase in overall AI-driven traffic over the same period (HUMAN Security, 2026). The divergence is the signature of long-running task agents and shopping agents that generate many more requests per finished task than a single chatbot answer.
HUMAN’s measurement counts agent runs across its customer network in 2025, not survey responses or projections. Each run hits the same product, comparison, and pricing pages a human buyer would visit, on a request pattern the page was never built to absorb, and on terms where the crawl-to-refer trade with publishers has already gone heavily one-sided.
Agents Transact, Humans Read
41% of B2B software buyers now name comparing vendor strengths and weaknesses as their #1 AI chatbot use case, ahead of basic product research and vendor identification (G2, 2026). Agents are running comparison and checkout steps inside a single conversation, and the unit of value on the page has moved from session length to extractable answer count.
The transactional shift shows up on both sides of the funnel. 67% of B2B buyers now prefer a rep-free buying experience (Gartner, March 2026), and Forrester’s 2026 State of Business Buying report finds buying groups doubling in size for purchases that include generative AI features as buyers turn to peers, providers, and agent output to validate the research (Forrester, 2026).
A page facing that audience has to answer a 13-stakeholder buying group’s questions through software that arrives, extracts, and leaves. The content asset that survives that traffic pattern is not the long-form essay; it is the sentence the agent can lift verbatim and hand back to the human in the loop.
Human Cognition Formatting Suppresses Agent Extraction
Adding statistics to a page boosts AI visibility 41% versus baseline (Princeton KDD, 2024). The lift is the difference between content that gets parsed and pulled into an agent answer and content that is technically present on the page but invisible to the retrieval pass.
The Princeton GEO benchmark scored five common content tactics across 10,000 queries.
| Tactic | AI visibility impact |
|---|---|
| Statistics addition | +41% |
| Quotation addition | +28% |
| Authoritative language | +25% |
| Fluency optimization | +15% |
| Keyword stuffing | -10% |
Agent retrieval rewards stat-attributed sentences, named-entity density, and direct claims, and penalizes prose padded with synonym variants and topical re-anchoring built for an older Google ranking model. The two optimization models point in opposite directions on the same page, so articles still written to a 2018 SEO brief carry a measurable visibility penalty in the new traffic even when their organic ranking has not yet reflected it.
55% of Agent Citations Come From the Opening Third
55% of citations from Google AI Overviews originate in the first 30% of the cited page (CXL, 2024). The opening third does roughly half the citation work, and pages that bury the lead stat into a background section forfeit that retrieval surface entirely.
Page architecture, not just word count, decides whether an agent finds the answer in time to cite it. RAG-style retrieval chunk-scores top-down and weights high-confidence early matches more heavily than later ones, so an article structured around a narrative arc that holds the data point until the conclusion is functionally invisible to retrieval. The same data point in the answer capsule of the first H2 typically registers.
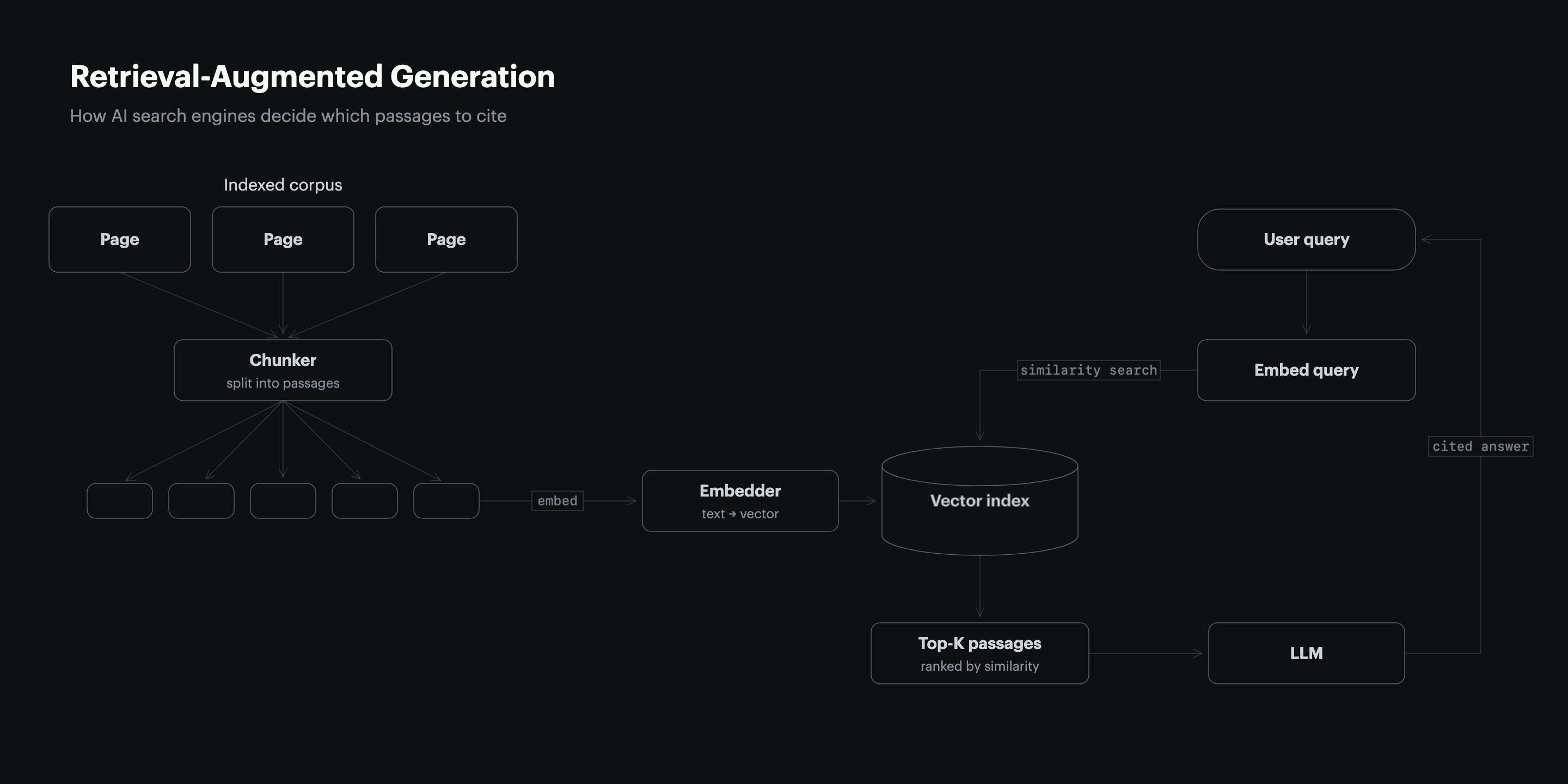
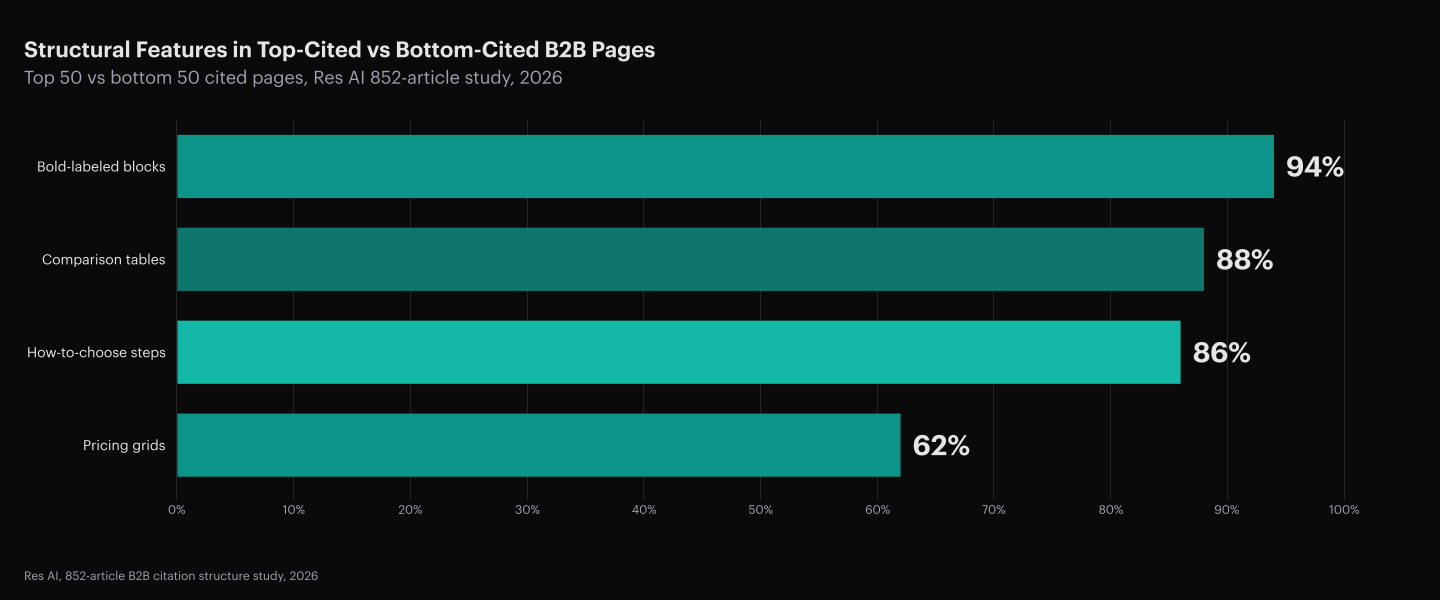
88% of Top-Cited B2B Pages Contain a Comparison Table
88% of the top 50 cited B2B pages contain a comparison table while 0% of the bottom 50 do, with a 4.5x structural element gap between the longest and shortest word-count quartiles (852-article B2B citation structure study, Res AI, 2026). The comparison table is the single most reliable predictor of which page an agent will lift an answer from.
The same study found 94% of top-cited pages used bold-labeled blocks, 86% used how-to-choose steps, and 62% used pricing grids, while the bottom 50 used 0% of any of them. Six features explain almost the entire structural gap. None of them are stylistic, and none of them appear naturally in a long-form essay written for a human reader.
Refresh Cadence Predicts Citation Persistence
Pages not updated quarterly are 3x more likely to lose AI citations than refreshed ones (AirOps and Kevin Indig, 2026). Agent-facing content has a much shorter half-life than evergreen SEO content, because retrieval rankings get resampled on roughly a monthly cadence rather than a multi-year one.
Profound’s 2026 measurement of citation drift across ChatGPT, Perplexity, Gemini, Copilot, and Google AI Overviews found 40% to 60% of cited domains rotate month over month on the same prompts, rising to 70% to 90% over six months (Profound, 2026). A page that was the answer in March can be missing entirely in April without a single change to the content itself, simply because the model resampled its retrieval pool against a refreshed competitor set.
85% of Agent-Readable Brand Mentions Originate Off Domain
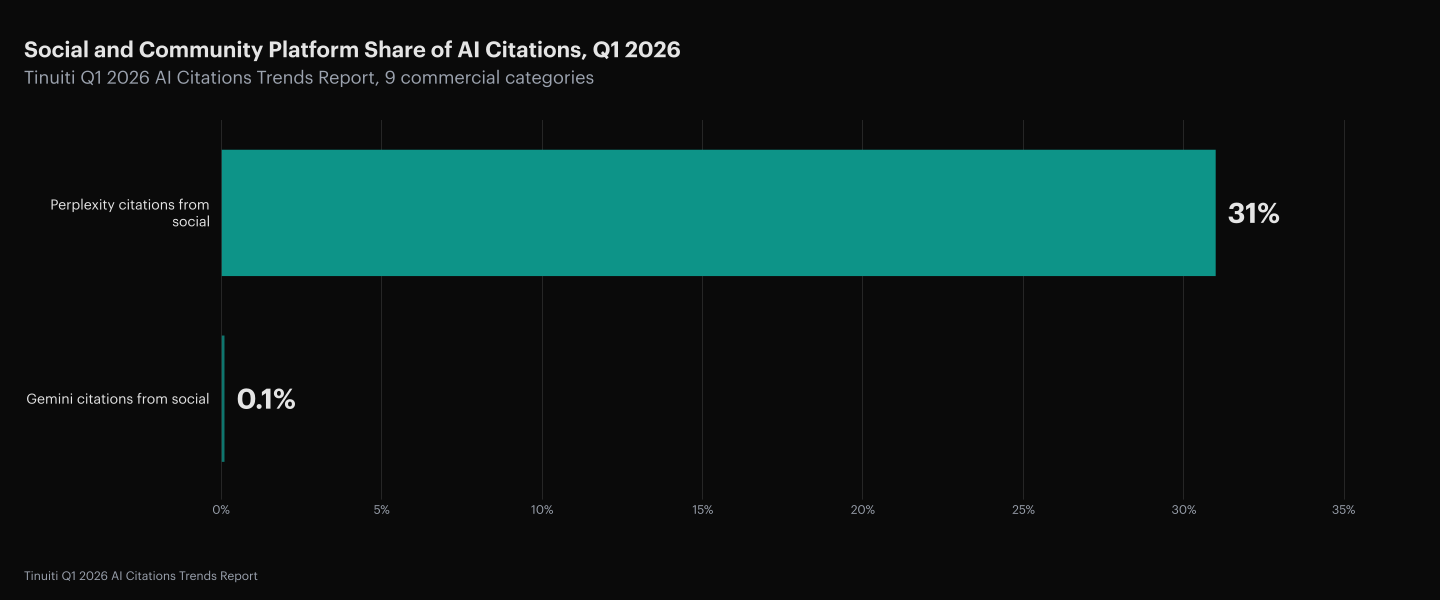
85% of brand mentions in AI search come from third-party pages, with 48% from community platforms like Reddit and YouTube (AirOps and Kevin Indig, 2026 State of AI Search). A content program that edits only its own domain reaches at most 15% of the surface that decides what an agent recommends to a buyer.
Reddit’s share of AI citations alone grew at least 73% across nine commercial categories in Q1 2026, pushing total social-media share above 9% of all AI citations, with Perplexity drawing 31% of its citations from social sources (Tinuiti, Q1 2026 AI Citations Trends Report). The agent’s view of a brand is overwhelmingly third-party. The owned page still sets the structural answer for the engines that fetch it, but a brand absent from the third-party retrieval surface is statistically unlikely to surface in the candidate pool at all.
AI Referral Conversion Now Runs 42% Above Non-AI
AI-referral conversion rate now runs 42% above non-AI channels, an 80-point year-on-year swing from March 2025 (Adobe Digital Index, Q1 2026). Agent and AI-influenced traffic, taken together, is now the highest-converting source on the typical retail and SaaS site, while still receiving the smallest share of structural editorial investment.
Adobe also measured AI visitors spending 48% more time on product pages and generating 37% higher revenue per visit than non-AI traffic (Adobe Digital Index, Q1 2026). Eyeful Media’s 2026 portfolio analysis put the conversion premium at 534% above site-wide average across B2B clients (Eyeful Media, 2026), and Semrush valued the average AI search visitor at 4.4x a traditional organic visit (Semrush, July 2025).
The traffic is small but disproportionately profitable, and it lands on whatever structural answer the page already had at the moment of retrieval.
Competitor Matrix
The GEO market splits along whether a tool measures the new agent traffic or actually rewrites the content for it, and that split decides whether the article on a buyer’s screen was ever built for the software now reading it. The matrix below compares named competitors on what they produce for agent-readable content, where the work physically ships, and what the team gets back.
| Tool | What it produces for agent-readable content | Where it ships | Output for the team |
|---|---|---|---|
| Res AI | Rewrites existing pages into agent-readable elements (tables, bold blocks, capsules) and generates net-new ones | Direct CMS deploy via natural-language edits | Published structural changes within minutes |
| Profound | Briefs and AEO articles for agent-readable surfaces | Standalone dashboard with brief handoff | Strategy briefs the team or agency executes |
| Conductor | Enterprise AEO recommendations layered on AI content production | Unified platform across AEO and SEO teams | End-to-end AEO workflows with collaboration |
| Peec AI | Visibility, position, and sentiment tracking with no content production | A monitoring dashboard, no editing layer | Tracking dashboards, no execution surface |
| Athena | Optimization recommendations across 8+ LLMs | Cross-platform tracking across 8+ LLMs | Optimization recommendations the team applies |
| AirOps | Multi-model content workflows targeting agent-readable structure | Multi-region content production pipelines | Pages and Pro workflows from creation to refresh |
Frequently Asked Questions
What kinds of agents are driving the 79x rise?
The growth is concentrated in long-running task agents that run multi-step research and actions on a buyer’s behalf and shopping agents handling product discovery and checkout. Both classes generate many more requests per finished task than chatbot Q&A, which HUMAN Security counts as a separate signal class entirely (HUMAN Security, 2026).
Why does the +41% Princeton stat-addition tactic apply to agent traffic specifically?
Agent retrieval rewards stat-attributed sentences and named entities because the chunk-scoring pass extracts factual claims, not topical relevance. The +41% lift Princeton measured for stat addition versus -10% for keyword stuffing reflects two different reading models being applied to the same page (Princeton KDD, 2024).
Do agents render JavaScript or rely on raw HTML?
Most production retrieval agents extract from server-rendered HTML or pre-fetched static representations because rendering JavaScript at agent scale is too expensive. Pages that gate critical content behind client-side rendering or interaction often deliver an empty shell to the agent and are silently passed over.
How should an owned content program account for the 85% of mentions it cannot edit?
The owned page sets the structural answer the agent extracts at retrieval, but the third-party surface decides whether the brand surfaces in the candidate pool at all. 85% of brand mentions come from third-party pages and 48% from community sources like Reddit and YouTube, so the structural rewrite on owned pages has to sit alongside earned third-party visibility, not replace it (AirOps and Kevin Indig, 2026).
Why does agent retrieval forget content faster than Google indexing does?
Retrieval rankings on AI engines get resampled on roughly a monthly cadence as models reweight their context, while Google’s organic index reranks but rarely fully rotates domains on the same query. Profound measured 40% to 60% citation drift month over month across major engines, with pages not updated quarterly 3x more likely to lose citations entirely (Profound, 2026; AirOps and Kevin Indig, 2026).
Why does the same edit register different citation outcomes depending on its position?
Retrieval pulls from the opening chunks of a page first because RAG systems chunk-score by position and weight high-confidence early matches more heavily. 55% of AI Overview citations come from the first 30% of the cited page, so the same comparison table earns very different citation outcomes at the top versus the bottom (CXL, 2024).
Why is conversion higher on AI-referred traffic if some of the visitor is software?
Adobe’s measurement isolates conversion at the human-visitor level after the agent or AI engine has already filtered the shortlist, with the human arriving more decision-ready than a typical organic visitor. AI-referral conversion rate now runs 42% above non-AI in March 2026, an 80-point year-over-year swing (Adobe Digital Index, Q1 2026).
How should a content team sequence a structural rewrite across an existing library?
Sequencing prioritizes pages by open agent-prompt volume rather than going library-wide all at once, since the citation lift opens at the first comparison table on a high-volume page, not at the 13th. The 852-article B2B citation structure study found a 4.5x structural-element gap between top and bottom cited pages, and a single high-volume page reorganization can move citations within weeks (852-article B2B citation structure study, Res AI, 2026).
How Res AI Restructures Existing Content for Agent Extraction
Res AI is execution first by design. The platform connects to the existing CMS, identifies the pages with the highest open agent-prompt volume, and ships structural edits like comparison tables, bold answer blocks, refreshed stats, and answer capsules into the live content library through a natural language interface, with no touch on the development pipeline. The same agent that reads buyer prompts on Perplexity, ChatGPT, and Google AI Overviews writes the structural change back into the CMS within hours, on the cadence the AirOps quarterly-refresh threshold demands.
The audit underwriting that workflow is the 852-article B2B citation structure study, which identified the six structural features present in 80% or more of top-cited pages and 0% of bottom-cited ones (Res AI, 852-article B2B citation structure study, 2026). Res AI’s content agent enforces those six features as a checklist on every published page, on a hours-to-days cadence rather than the agency brief cycle that ships in weeks.
Res AI turns existing content into agent-readable structure on the same cadence as the agent traffic itself. The platform monitors open prompts across ChatGPT, Perplexity, Gemini, and Google AI Overviews, then ships table, bold-block, and capsule edits directly into the live CMS through a natural language prompt.