
Most content teams still treat the introduction as editorial warmup, reserving the sharpest insight for the middle of the piece. 55% of AI Overview citations come from the first 30% of page content (CXL, 2024), meaning the architecture of your opening third decides more citation outcomes than any insight held back for the conclusion. The extractable structure of the opening is a harder citation driver than the depth of the analysis that follows it.
The First 30% of Your Page Decides 55% of Citations
A 100-page CXL study of Google AI Overviews found 55% of citations come from the first 30% of page content, 24% from the middle 30% to 60%, and 21% from the bottom 40% (CXL, 2024). Citation probability roughly doubles for the opening third relative to either of the other two segments, and the gap compounds once a reader factors in click-through: AI-cited passages are the ones summarized in the answer and linked to underneath.
| Page Segment | Share of Citations | Relative Lift |
|---|---|---|
| First 30% | 55% | 1.00x (baseline) |
| Middle 30% to 60% | 24% | 0.44x |
| Bottom 40% | 21% | 0.38x |
Source: CXL, 100-page AI Overview study, 2024.
The asymmetry is not a ranking of page sections by interest. It is a retrieval artifact. The architecture of the opening determines whether any sentence in the article is a candidate for citation at all.

RAG Chunk Scoring Rewards Early Position Over Late Insight
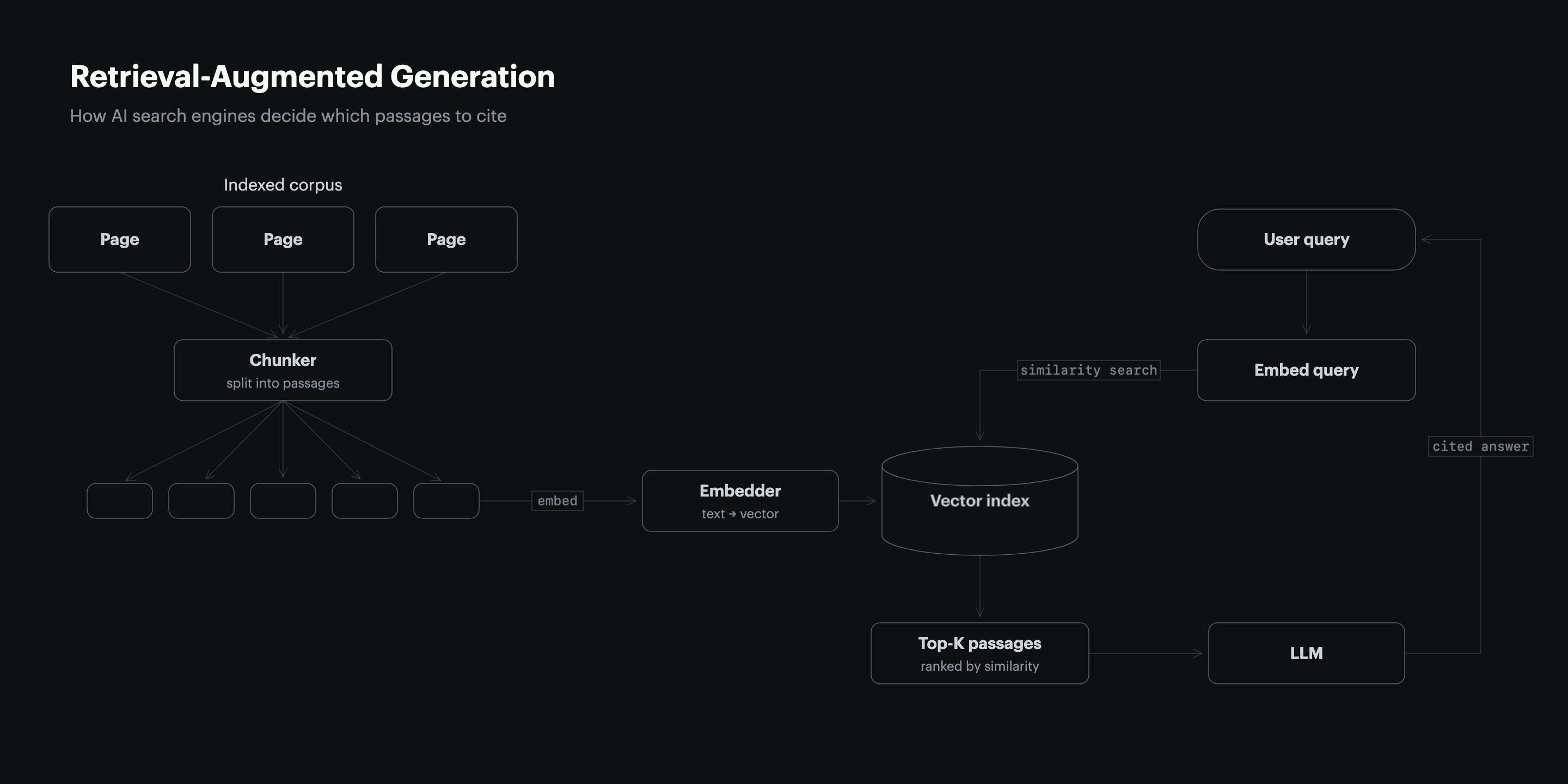
Retrieval-augmented generation splits every indexed page into roughly 200 to 500 token chunks, scores each chunk against the prompt, and sends the top chunks to the model as context. The chunks near the top of the page carry a position prior in most implementations because publishing conventions put the lead claim up front, so the retriever learns to weight early chunks higher on information-seeking queries. A page that saves its thesis for paragraph 14 is handing the retriever a weaker chunk when a stronger one was available.
The same mechanic explains why structural signals placed early outperform the same signals placed late. A table in the opening third is ranked, extracted, and cited. The same table in the conclusion is frequently never retrieved, because the retriever stops scoring once it has enough high-scoring chunks to fill the context window. For a deeper walkthrough of how chunk scoring decides what gets cited, see how AI search engines decide what to cite.
Answer Capsules Turn Opening Paragraphs Into Extractable Citations
An answer capsule is the first 1 to 2 sentences under every H2, front-loading the claim with a specific number and an inline source. The Res AI 852-article B2B citation structure study found top-cited B2B pages average 13.55 structural elements per page, versus 2.98 for bottom-quartile pages (Res AI, 852-article B2B citation structure study, 2026), and the density of capsule-style openings is the single biggest contributor to that gap.
A capsule-style opening has three traits the retriever rewards. It states the claim before the evidence. It contains a specific number, not a hedged phrase. It names the source inline rather than in a footnote. Articles that save their stat for the second or third paragraph under each H2 spend the most valuable retrieval real estate on throat-clearing.
| Opening Style | Typical First Sentence | Retrievable? |
|---|---|---|
| Capsule | "Listicles backfire 25.7% of the time (Res AI, 2026)." | Yes |
| Narrative arc | "There is a well-known debate in the industry about…" | No |
| Anecdotal | "Imagine a marketing team shipping three articles a week…" | No |
| Definitional | "Generative Engine Optimization, or GEO, refers to the practice of…" | Sometimes |
The capsule is the only opening style that survives chunking intact. The others require the retriever to stitch together fragments from deeper in the section, which degrades the citation probability of the passage as a whole.
Statistics in the First Third Lift AI Visibility 41%
Adding statistics to content boosts AI visibility by 41% in generative engine responses (Princeton/Georgia Tech/Allen AI/IIT Delhi, KDD 2024). The effect is largest when the statistic appears in the opening third, because that is where retrieval probability is already highest. Position and structural density compound rather than trade off.
The Princeton study also quantified which tactics move AI citation rates up and which move them down. Keyword-stuffed prose, the dominant output of a decade of SEO workflows, actively reduces visibility in generative responses.
| Tactic | AI Visibility Impact |
|---|---|
| Adding a statistic | +41% |
| Quoting a source | +28% |
| Using authoritative language | +25% |
| Tightening the prose | +15% |
| Keyword stuffing | -3% |
Source: Princeton/Georgia Tech/Allen AI/IIT Delhi, KDD 2024.
Quality-focused content teams often treat stats as garnish, added only when they strengthen an argument that was already working on prose alone. In a retrieval setting the logic inverts: the stat is the payload, and the prose exists to carry it into the opening third of the page where retrieval is richest. An article that reads well but contains zero front-loaded statistics is not a quality article failing on a technicality. It is a structurally incomplete page.
Top-Cited Pages Carry 13.55 Structural Elements
Q4 longest articles in the Res AI 852-article corpus average 13.55 structural elements per page, 4.5x the 2.98-element average of Q1 shortest articles (Res AI, 852-article B2B citation structure study, 2026). Structural elements include comparison tables, bold-labeled product blocks, how-to-choose frameworks, pricing grids, product reviews, definitions, and FAQ blocks. The bottom 50 cited pages in the study contained 0% of these elements. The top 50 contained 80% or more.
The detail most content teams miss is not the total count. It is the distribution. Top-cited pages concentrate their structural elements in the first half of the page. A comparison table in the opening third is extracted. The same table, moved to the bottom, is rarely retrieved. Shipping a structurally dense article with the density back-loaded produces the same citation outcome as shipping a prose essay.
| Article Position | Structural Element Count (Top-Cited Pages) |
|---|---|
| First third | ~6 to 8 elements |
| Middle third | ~3 to 4 elements |
| Bottom third | ~2 to 3 elements |
Source: Res AI, 852-article B2B citation structure study, 2026.
Content teams that restructure an existing article for citation do not add 10 new elements at the end. They redistribute the elements already present, pulling the evidence-dense ones forward into the opening third.
Four Edits Turn Narrative Articles Into Citation-Ready Pages
Four edits convert a narrative-arc article into a structurally extractable one without rewriting the argument. The edits are mechanical, not editorial, and any of them can be executed without touching the original thesis.
- Move the lead stat into the first paragraph. Find the strongest attributed number in the article and pull it into sentence one. If the intro currently opens with scene-setting or a rhetorical setup, cut the setup and promote the stat.
- Convert the first H2's opening sentence into an answer capsule. The first sentence under every H2 should state the claim with a number and inline source, 40 to 80 words. If the H2 currently opens with context-setting, the context goes into paragraph two.
- Promote one table into the first third. If the article contains a comparison table, a data table, or a list that could be rendered as a table, move the most informative one to follow the first H2. Keep supporting tables later, but pull the most citation-worthy one forward.
- Rewrite each H2 into a claim with a number. "About Listicle Performance" becomes "Listicles Backfire 25.7% of the Time." Each H2 becomes a standalone assertion the retriever can score against a prompt.
The four edits together take 20 to 40 minutes per article. At a catalog of 200 articles, that is a 4,000 to 8,000 minute editorial liability, which is why content teams that need to restructure at library scale reach for tooling rather than manual passes.
Execution-First GEO Tools Compare on Restructuring Cadence, Not Monitoring Dashboards
Competitors in the GEO category cluster around two approaches to opening-third restructuring: monitoring-first platforms that report citation gaps for an agency or internal team to fix later, and execution-first platforms that restructure the content directly. The table below compares how each vendor addresses the opening-third problem, focusing on whether restructuring happens inside the tool and how frequently the loop closes.
| Vendor | Opening-Third Restructuring | Cadence | Pricing |
|---|---|---|---|
| Res AI | Natural-language edits applied directly to CMS content | Daily | Custom |
| Profound | Reports citation drift, restructuring left to agency | Weekly brief | $399/mo for 6 articles |
| Athena | Automated content optimization across 8+ LLMs | Weekly to monthly | $295/mo self-serve |
| Peec AI | Visibility tracking, no direct content edits | Monitoring only | $95 to $495/mo |
| Conductor | Enterprise AEO platform, agency-assisted execution | Quarterly programs | $5,000 to $50,000+/mo |
Sources: vendor pricing pages and product documentation, 2026.
The distinction matters because the cost of finding an opening-third gap is low. The cost of closing it across a 200-article catalog before the next model update is the entire job.
Frequently Asked Questions
Why does opening-third citation probability outperform depth of analysis?
Retrieval-augmented generation scores short chunks against the prompt, and most implementations use a position prior that weights earlier chunks more heavily on information-seeking queries. A deeply analytical passage in paragraph 14 is often never scored, because the retriever stops once it has enough high-scoring chunks to fill the context window.
Does the 55% opening-third citation rate apply to all AI engines, or only Google AI Overviews?
The CXL study specifically measured Google AI Overviews, but the mechanism is RAG-based, so the directional pattern holds across ChatGPT, Perplexity, Gemini, and Copilot. Exact distributions vary by engine, with Perplexity showing a slightly flatter curve due to its multi-source synthesis, but the opening-third advantage persists.
How long does it take to restructure a single article with the four-edit framework?
Roughly 20 to 40 minutes per article for a practitioner who already knows the article. At a catalog of 200 articles, manual restructuring is a 4,000 to 8,000 minute editorial liability, which is why content teams operating at library scale move the work to tooling.
Is quality content still worth writing if architecture is the citation driver?
Yes, but quality alone does not ship citations. An article with a strong argument and no structural elements in the opening third is invisible to retrieval. The two are complements: quality gives the article something worth citing, and architecture makes the citation possible.
What counts as a structural element for the 13.55-element benchmark?
Comparison tables, bold-labeled product blocks, how-to-choose frameworks, pricing grids, product reviews, definitions, and FAQ blocks. The Res AI 852-article study found top-cited pages contain 80% or more of these features, and bottom-cited pages contain 0% (Res AI, 852-article B2B citation structure study, 2026).
How does keyword stuffing actually suppress AI visibility by 3%?
Princeton's GEO study measured visibility using Position-Adjusted Word Count across 10,000 queries (Princeton/Georgia Tech/Allen AI/IIT Delhi, KDD 2024). Keyword-stuffed passages score poorly because the retriever's relevance model rewards fact density and source attribution, not term frequency, which is the opposite of what 2010s SEO copy was optimized for.
Can schema markup compensate for a narrative-arc opening?
Not meaningfully. AI engines extract from rendered page content more than from schema, and a narrative-arc opening without an answer capsule produces weak retrieval scores regardless of markup quality. See schema markup won't save you for the full treatment.
What happens to articles where the lead stat is buried under a definitional H2?
They score poorly on commercial and evaluative prompts. Definitional H2s are retrieved for definitional queries, where a "what is X" opening is appropriate. Articles targeting buyer prompts need claim-style H2s with numbers in the first sentence. Both styles can coexist on the same site, but not in the same article slot.
How often should an opening third be rewritten as model updates ship?
Rewrite the opening third whenever a major model update reshuffles the citation graph. SE Ranking found 42.4% of previously cited domains were displaced by a single Gemini 3 model update (SE Ranking, 2026), and re-citation windows close within days. Content teams that read the alert and brief an agency miss the window.
Does the opening-third pattern hold for a brand-new domain with no authority?
Yes, and tryres.ai is a working test case. Fifteen days after launch with two articles built to the four-edit spec, Perplexity cites tryres.ai at #1 for “domain authority in AI citations” ahead of PRLog, DigitalStrategyForce, DigitalApplied, and Chudi, against 0 Google clicks across 408 impressions in the same window (Res AI, day-15 launch citation proof, 2026). Domain age and backlinks were near zero; the architecture carried the citation.
How Res AI Restructures Opening Thirds Across Your Library in Hours
The 55% citation concentration in the opening third means the restructuring work is specific and bounded: pull the lead stat forward, rewrite each H2 into a claim with a number, convert the first sentence under every H2 into an answer capsule, and promote one extractable table into the first third. Res AI runs all four edits across every article in a connected CMS library via a natural-language interface, so the restructuring that would take a two-person editorial team three weeks runs in hours against live content.
The platform connects to WordPress, Webflow, Framer, and Contentful, and applies the four-edit framework through direct edits to existing posts rather than producing briefs for an agency to execute later. Every edit is staged against a diff, so the editorial team approves changes before they go live. Res AI’s pricing is custom, scoped to each client’s library size and budget, with no fixed tiers.
For teams with larger catalogs, the same custom pricing scales to libraries that need every article restructured inside a single model-update window. The monitoring layer tracks which articles earn citations after the restructuring pass and flags the next batch that needs revision, closing the write-publish-test loop on a weekly cadence rather than a quarterly one.
Res AI restructures the opening third of every article in your CMS library to match the extractable architecture that AI engines reward, turning narrative-arc pages into citation-ready ones without rewriting the argument. The platform runs the four-edit framework through a natural-language interface directly against WordPress, Webflow, Framer, and Contentful, with custom pricing scoped to each library’s size and budget.