
Most SaaS marketing teams can report how many pageviews an article earned last quarter. Far fewer can say whether ChatGPT, Perplexity, or Gemini cited that same article when a buyer asked which tool to shortlist, even though 84% of B2B SaaS CMOs now use AI assistants for vendor discovery (Wynter, 2026). Content monitoring closes that blind spot by tracking whether your published pages surface in AI answers, explaining why they appear or vanish, and pointing to what needs to change.
What Content Monitoring Means in AI Search
Content monitoring is the practice of checking whether your published pages are cited by AI answer engines and acting on what the results show. It is the AI-search successor to keyword rank tracking, and it matters because 51% of B2B software buyers now begin research with an AI chatbot rather than a search engine (G2, 2026). The surface a SaaS team needs to watch is the generated answer, not the list of blue links underneath it.
Four terms separate a useful monitoring practice from a vague one.
Answer engine. An AI system that generates a written answer instead of a link list. ChatGPT, Perplexity, Gemini, and Claude are the four a SaaS team should track.
Citation. A link to one of your pages used as a named source inside an answer. Citations are countable and verifiable, which makes them the core unit of monitoring.
Brand mention. Your company named in an answer with no link to your site. A mention builds recall; a citation drives a visit.
Prompt. The natural-language question a buyer types. Prompts, not keywords, are the unit of measurement in AI search.
The engines worth monitoring are not interchangeable, and a page that wins on one can be absent on another.
| Engine | Why it matters for SaaS buyers | Monitoring note |
|---|---|---|
| ChatGPT | Reached 900M weekly users and is the most common research starting point | Cited domains shift with each model update |
| Perplexity | Search-native and shows its sources on every answer | The easiest engine to read citations from directly |
| Google Gemini | Powers AI Overviews and overtook Perplexity for referral traffic | The same page can win or lose after a model swap |
| Claude | A fast-growing referral source for SaaS product signups | Its cited domains differ sharply from ChatGPT |
A team formalizing this for the first time can start from the B2B SaaS guide to AI citation monitoring, which covers the tooling landscape in more depth.
How AI Engines Decide Which Pages to Cite
AI engines do not rank whole pages, they retrieve and quote individual passages, and 55% of AI citations come from the first 30% of a cited page’s content (CXL, 2024). An engine splits each page into chunks, embeds them as vectors, and pulls the few passages that most closely answer the prompt. Monitoring without this model in mind tells you that you lost a citation but never why.
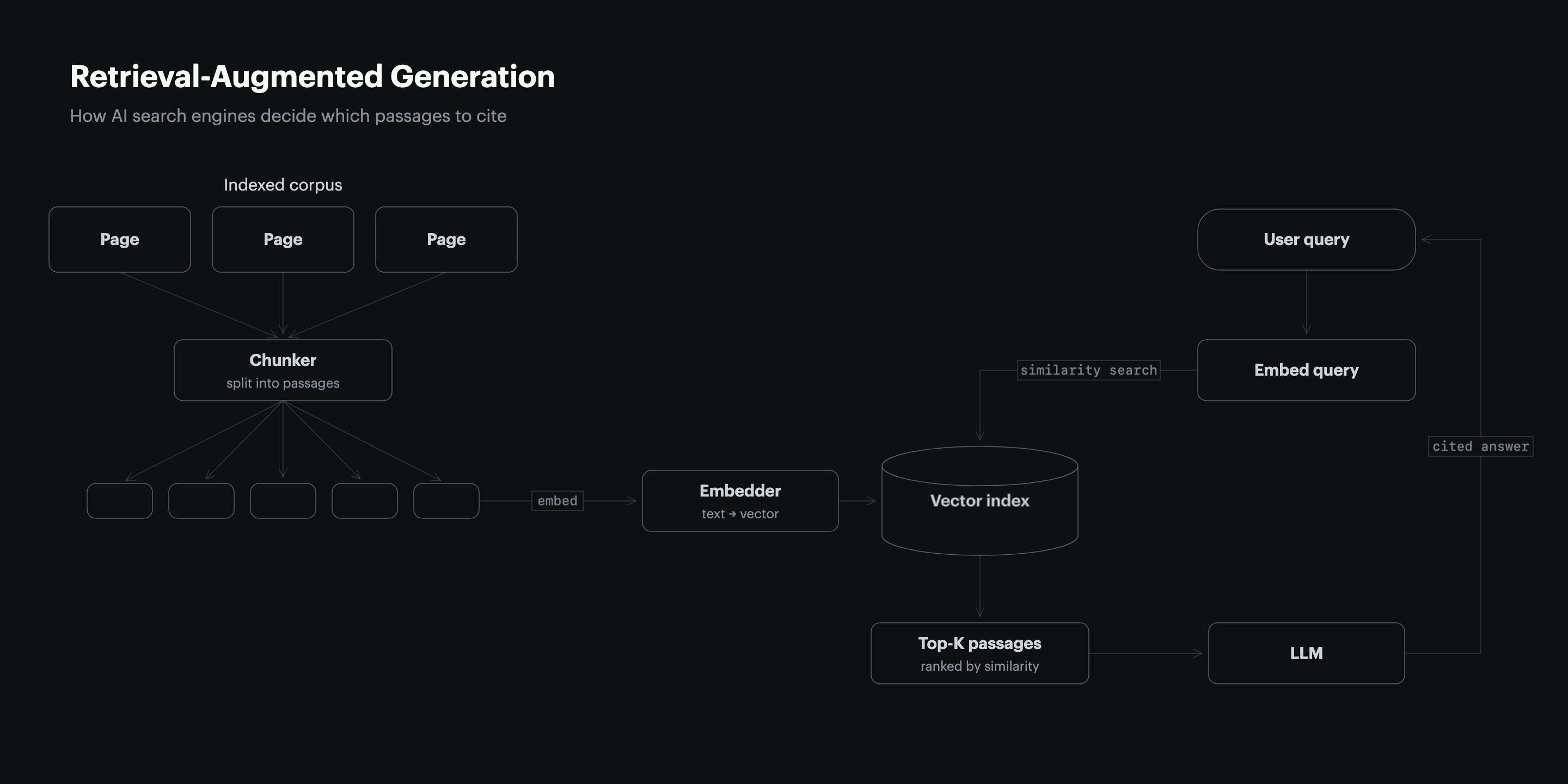
Two facts follow from this mechanism. First, structure decides retrieval more than domain size: a 1,000-query B2B AI citation structure study found non-giant domains held the stable #1 citation position on 93 of 100 B2B queries (Res AI, 2026). Second, a page can be genuinely excellent and still go uncited because its answer is buried below the opening third. Monitoring should therefore record which passage was quoted, not just whether the domain appeared, so the fix is obvious. The full retrieval mechanics are covered in how AI search engines decide what to cite.
Why Citations Drift From Month to Month
AI citations are not stable rankings, they decay. Between 40% and 60% of the domains cited in one month are absent the next for the identical prompts (Profound, 2026). A page cited in March can be gone in April with no edit on your side, which is the single clearest reason content monitoring has to be a recurring measurement rather than a one-time audit.
Model updates are the largest cause of drift. When Google made Gemini 3 the default for AI Overviews, 42.4% of previously cited domains stopped appearing and were replaced by a fresh set (SE Ranking, 2026). Drift is also why a snapshot misleads: a check that catches you on a good run reads as a permanent win, and a check on a bad run reads as failure. Treating either as stable is the gap monitoring-first GEO platforms leave open when their alert cadence is slower than the drift itself.
Why Brand Mentions and Citations Are Different
A brand mention names your company in an answer; a citation links to a specific page of yours as a source. 85% of brand mentions originate from third-party pages rather than your own domain (Airops, 2026). Monitoring that counts only one of the two gives a distorted picture of where a SaaS brand actually stands in AI answers.
The distinction changes what you do next. If you are mentioned but not cited, the answer trusts your brand but pulled its supporting detail from a review site or a competitor’s comparison page. If you are cited, one of your pages is doing the work and you can identify exactly which one. A monitoring log should track both columns separately, because they point to different fixes: earning a mention is a reputation and third-party-coverage problem, while earning a citation is a structure problem on a page you control. Brands that earn both a citation and a mention are 40% more likely to resurface in the next answer (Airops, 2026), so the two reinforce each other once both are tracked.
Inventory the Prompts Your Buyers Actually Run
Begin by listing the real questions your buyers ask an AI assistant, not the keywords they once typed into Google. A prompt inventory is the backbone of every later step, because you cannot measure citations for questions you never wrote down.
Prompts cluster into a few recurring shapes: category questions (best onboarding software for SaaS), comparison questions (one tool versus another), and use-case questions (how to reduce trial churn). Pull the raw material from the places your buyers already leave it rather than inventing prompts at a whiteboard.
| Source | What it reveals | Example prompt it yields |
|---|---|---|
| Sales discovery calls | The exact wording buyers use for problems | “What tool fixes low trial activation” |
| Support tickets | Use-case and integration questions | “Does this integrate with Salesforce” |
| Won and lost deal notes | The head-to-head comparisons buyers ran | “Best alternative to the incumbent we replaced” |
| Your own AI test runs | Gaps where a competitor is named and you are not | “Best mid-market option for this category” |
Aim for 20 to 50 prompts at the start. That range is large enough to be representative of real buyer intent without making manual checks unmanageable in the first month.
Run Each Prompt Across Every Engine Separately
Check every prompt on ChatGPT, Perplexity, Gemini, and Claude as separate tests, never as a single blended score. The engines retrieve from different indexes and reward different page structures, so one combined number hides exactly the gaps you set up monitoring to find.
The overlap between engines is small: only 11% of cited domains appear in both ChatGPT and Perplexity for the same queries (Averi, 2026). Engine share also moves quickly, and Gemini overtook Perplexity as a referral source in January 2026, sending 29% more visitors to websites that month (SE Ranking, 2026). A prompt you win on Perplexity may be a prompt you lose on Gemini, and an averaged score would never surface that. Run each engine, log each result, and resist collapsing them into one figure. A single check on a single engine is the weakest possible signal, as one citation check cannot measure GEO performance sets out in detail.
Log Citations at the Page and Passage Level
Record more than a yes or no. For every cited result, log which page was retrieved and which passage was quoted, because that pair is what tells you whether to fix an existing page or build a new one.
A monitoring log that only stores “cited: yes” cannot drive any action. The minimum useful record has six fields, and each one maps to a later decision.
| Field to log | What it answers | Example entry |
|---|---|---|
| Prompt text | Which buyer question was asked | “best onboarding software for SaaS” |
| Engine and date | Where and when you checked | Perplexity, 2026-05-12 |
| Cited or not | Did your domain appear as a source | Yes, source 3 of 8 |
| Cited URL | Which exact page was retrieved | /resources/onboarding-guide |
| Cited passage | Which section of the page was quoted | The pricing comparison table |
| Competing domains | Which other domains the answer cited | A review site and two competitor blogs |
The competing-domains column matters most. When an answer cites a competitor instead of you, that competitor’s page is both your benchmark and your target, and the passage column tells you what structure to match.
Set a Refresh Cadence Before Citations Decay
Schedule content refreshes on a fixed calendar rather than waiting for a citation to disappear. Monitoring tells you a page slipped; a refresh cadence is what stops the slip from becoming permanent.
Pages not updated at least quarterly are 3x more likely to lose their citations (Airops, 2026). Vercel runs a 30, 90, and 180-day refresh schedule for AI-targeted content and grew ChatGPT-referred signups from under 1% to 10% over six months (Vercel, 2026). The cadence does not need to be elaborate to work.
Re-verify the highest-value prompts monthly, sweep the long tail quarterly, and trigger an off-cycle refresh whenever the monitoring log shows a competitor displacing you. Speed compounds here, because Semrush saw its AI share of voice nearly triple within a single month of restructuring content (Semrush, 2025). A cadence turns monitoring from a passive report into a maintenance schedule.
Measure Citation Rate Across Runs, Not Snapshots
Measure the share of runs in which you are cited, not a single pass or fail. AI answers are non-deterministic, and asking ChatGPT or Google the same question 100 times yields the identical brand list less than 1% of the time (SparkToro, 2024). A citation rate of 7 of 10 runs is a real signal; a single check is noise dressed as data.
The 1,000-query Perplexity B2B citation study ran each query 10 times and measured a Jaccard similarity of just 0.72 between any two runs (Res AI, 2026). The practical floor is roughly 10 runs per prompt per engine, which is enough to average out variance without exhausting a small team’s time.
| Property | Snapshot check | Citation-rate monitoring |
|---|---|---|
| What it reports | Cited or not on one run | Share of runs cited, such as 7 of 10 |
| False-negative risk | High; one unlucky run reads as zero | Low; the rate averages out variance |
| Detects drift | No | Yes, the rate trends month over month |
| Points to a fix | No | Partly, when paired with passage logs |
A score that ignores run variance is the reason an AI visibility score can mislead a team into believing a page is safe when it is not.
Match Your Monitoring Approach to Your Stage
The right monitoring setup depends on how much content you have published and how fast it drifts. A 15-page startup and a 300-page content team should not monitor the same way, and copying the heavier process onto the smaller library wastes time the small team does not have.
| Your situation | Where to start monitoring | Why it fits |
|---|---|---|
| Fewer than 20 published pages | Manual checks on 5 to 10 core prompts | The volume is low enough to read by hand |
| 20 to 200 pages, one marketer | A monitoring tool plus a fixed refresh cadence | Manual runs across four engines no longer scale |
| 200+ pages and a content team | A platform that monitors and edits in one place | Drift outpaces a brief-and-publish cycle |
| Citations appear then vanish fast | Multi-run tracking on a weekly cadence | Snapshots miss the re-citation window entirely |
Two rules hold at every stage. Monitoring is only worth the effort if it ends in a content change, and a dashboard nobody acts on is a cost rather than an asset, which is the argument you do not need to monitor your AI visibility, you need to create it makes in full. The buyer is also already deep in the AI channel before you ever see them, since 67% of B2B buyers now prefer a rep-free buying experience (Gartner, 2026), so the answer engine is doing the qualifying whether a SaaS team monitors it or not.
How GEO Monitoring Tools Compare
Every tool in the GEO category addresses the same problem, knowing whether AI engines cite your content, but they cluster around two approaches: report the gap, or report it and close it. The matrix below compares them on what each one monitors, how many engines it covers, and what the team actually receives back.
| Tool | What it monitors | Engines tracked | What the team gets back |
|---|---|---|---|
| Res AI | Citation performance and the page structure that earns it | ChatGPT, Perplexity, Claude, Gemini | Restructured pages published to the CMS, not just a report |
| Profound | Brand visibility across answer engines | 10+ engines including Copilot, Grok, Meta AI, and Rufus | Analytics dashboards and buyer prompt volumes |
| Conductor | AI visibility alongside traditional search | ChatGPT, Gemini, Copilot, Claude, and Google | Unified AEO and SEO reporting for enterprise teams |
| Peec AI | Visibility, position, and sentiment per prompt | Multiple LLMs with region-specific results | Which content sections triggered each citation |
| Athena | Visibility plus citation-source authority | 8+ LLMs including AI Overviews and Grok | Automated optimization recommendations |
| AirOps | Content performance across AI search and Google | ChatGPT and other major AI models | Content generated across 30+ AI models |
The split that decides a monitoring program is the last column. Four of these tools hand back a report or a dashboard, and the SaaS team still owns the edit, the brief, and the wait for a developer.
Frequently Asked Questions
How often should a SaaS team check its AI citations?
Re-verify your highest-value prompts monthly and sweep the long tail quarterly. Citation drift runs 40% to 60% month over month (Profound, 2026), so a quarterly-only cadence misses most of the movement.
Can Google Search Console show whether ChatGPT cited a page?
No. Search Console reports Google search impressions and clicks, not citations inside ChatGPT, Perplexity, or Claude. AI engines do not feed that data to any analytics tool, so citations have to be checked against the engines directly.
Is a high AI visibility score the same as being cited?
Not necessarily. A blended visibility score can rise on brand mentions while your pages earn no citations, and 85% of brand mentions come from third-party domains rather than your own (Airops, 2026). Track citations to your own URLs as a separate number.
Should I monitor ChatGPT and Perplexity together or separately?
Separately. Only 11% of cited domains overlap between the two engines (Averi, 2026), so a combined score hides the specific engine where a page is losing.
What is the difference between content monitoring and a one-time citation audit?
An audit is a single snapshot, while monitoring is a repeated measurement that tracks change over time. Because AI answers vary from run to run, only the repeated version can separate a real trend from random noise.
How long after publishing should a page appear in AI answers?
Often within days, not the months traditional SEO requires. Res AI’s day-15 launch citation proof documented Perplexity citing two articles as primary sources 15 days after launch (Res AI, 2026).
Why did a page that was cited last month disappear from AI answers?
The most common cause is a model update reshuffling the retrieval index. When Gemini 3 became the AI Overviews default, 42.4% of previously cited domains dropped out (SE Ranking, 2026), usually with no change at all on the publisher’s side.
Do I need a paid tool to monitor AI citations?
Not at first. A team with fewer than 20 pages can track 5 to 10 prompts by hand across four engines, and paid tools earn their place once the prompt list and page count outgrow manual runs.
How does content monitoring connect to actually fixing the content?
Monitoring is only useful when it ends in an edit. The passage and competing-domain logs tell you which page to restructure, and the refresh cadence schedules that work before the citation is lost for good.
How Res AI Closes the Monitoring-to-Publishing Gap
Every step in this guide ends at the same place: a monitoring log that names a page to fix. Res AI is built to act on that log rather than file it. Its Strategy Agent tracks the prompts buyers run across ChatGPT, Perplexity, Claude, and Gemini and flags where a competitor is cited instead of you, and its Content Agent restructures the losing page into the tables, comparison blocks, and FAQ sections AI engines extract.
The difference from a monitoring-only tool is the last mile. Res AI connects directly to 9 CMS platforms, including WordPress, Webflow, Framer, and Contentful, so a flagged page can be rewritten and republished in minutes without a developer. Monitoring tells a SaaS team a citation slipped; Res AI is the mechanism that puts the page back.
Res AI turns content monitoring into content correction, restructuring the pages that lost AI citations and publishing them straight to your CMS. Its agents track buyer prompts across ChatGPT, Perplexity, Claude, and Gemini, then rewrite the pages losing those prompts with no developer involved.