7 Brands Winning AI Search in 2026 (and What They Built)
Tally, Vercel, Rippling, Scrupp, Spellbook, Stitchflow, Userlytics. 7 brands holding first-position AI citations. Two structural paths. One repeatable system.
 machina sculpsit · homo probavit · MMXXVI
machina sculpsit · homo probavit · MMXXVIAI-referred visitors convert at 4.4x the rate of traditional organic search visitors, according to Semrush’s analysis of over 500 high-value B2B topics (Semrush, July 2025). The seven brands in this article hold first-position AI citations on their highest-intent buyer queries, not because they outranked anyone on Google, but because they built content in a format AI engines can extract and verify. What they built is different in each case. The mechanisms are not interchangeable.
Not Every Winner Built the Same Thing
84% of B2B SaaS CMOs now use AI for vendor discovery, up from 24% in 2025, but the structural approaches producing citations differ significantly by company type and category position (Wynter, 2026). Two paths account for most of the results below. A third case stands on its own.
Path 1: Structural density. FAQ sections, comparison tables, and third-party attributed statistics applied systematically to every page targeting a buyer query. This is Tally’s path, Rippling’s path, Scrupp’s path, Stitchflow’s path, and Userlytics’ path. It works because AI retrieval systems extract self-contained answers. A page with 9 FAQ sections and a G2 ratings comparison answers 9 distinct buyer queries; a page with 0 FAQs and 30 internal links answers none.
Path 2: Coverage breadth. Reviewing 10 to 13 named competitors in a single article, making one page the reference point for every query in the category. Spellbook uses this path. It works when a brand already has enough category authority for the coverage to amplify an existing signal. Coverage breadth without category authority is just a long page.
Vercel is a third case. They built structural density, engineered community citation seeding across GitHub, Reddit, and Hacker News, then published the methodology with their CTO as co-author. It is the most documented intentional GEO case on record.
How to choose the right path for your situation:
| If your situation is... | Prioritize... |
|---|---|
| Small brand, crowded query, low domain authority | Structural density: 8+ FAQs per comparison page, third-party attribution, comparison tables |
| Mid-size brand with 10+ named competitor relationships | Coverage breadth: one comprehensive alternatives page covering all named competitors |
| Developer-facing brand with active community channels | Community seeding + structural density: structured docs plus GitHub, Reddit, Stack Overflow citation seeding |
| Enterprise brand with existing content library | Systematic retrofitting: apply the structural spec across existing pages at scale |
These paths are not mutually exclusive. Rippling runs structural density across 18 comparison pages simultaneously. That is Path 1 applied at Path 2 scale.
Tally’s Claude Referrals Are Now Growing Faster Than ChatGPT
As of April 2026, Claude is growing faster than ChatGPT as a referral source for Tally, which reached $422,000 in monthly recurring revenue with no paid marketing and a team of 11 (Tally, April 2026). The mechanism is structural tracking at the prompt level: Tally’s post-signup onboarding survey captures which specific AI queries drove each new user, creating a feedback loop that shapes every page they build next.
The feedback loop is operationally simple but rare. When a new user says “ChatGPT recommended it” in onboarding, Tally logs which prompt they used. Over time, that data reveals which buyer queries are actively driving signups and which are not yet covered. The comparison pages Tally builds are a direct response to those gaps, not a keyword-research exercise.
The result is multi-engine diversification by design. Tally holds citation positions on ChatGPT, Claude, and Gemini simultaneously for “best free form builder” and “free Typeform alternative” queries. The 2% free-to-paid conversion rate on Tally Pro (Tally, April 2026) means AI-referred users are not just traffic; they are a predictable revenue funnel. The Tally MCP server, launched in 2026, extends the model further: Claude, ChatGPT, and Cursor can now build and analyze forms through conversation, making Tally the natural output when any of those tools field a form-builder request.
Query won: “best free form builder,” “free Typeform alternative” Incumbent beaten: Typeform (structural audit in Typeform vs. Tally) Structural feature: 6 to 9 FAQ sections per comparison page, onboarding-survey-driven prompt tracking, multi-engine MCP presence
Vercel’s CTO Published a 5-Step AI Search Playbook
ChatGPT referral signups at Vercel grew from under 1% to 4.8% and then to 10% of all new signups over six months, a trajectory Malte Ubl, Vercel’s CTO, co-authored a public post documenting after it happened (Vercel, June 2025). The post names five structural tactics executed in sequence: static HTML rendering via SSR/SSG/ISR so LLM crawlers access the full page; Schema.org and JSON-LD markup; clean heading hierarchies (H1, H2, H3); semantic HTML including definition lists, tables, and ARIA labels; and citation seeding on GitHub, Reddit, Hacker News, LinkedIn, and Stack Overflow.
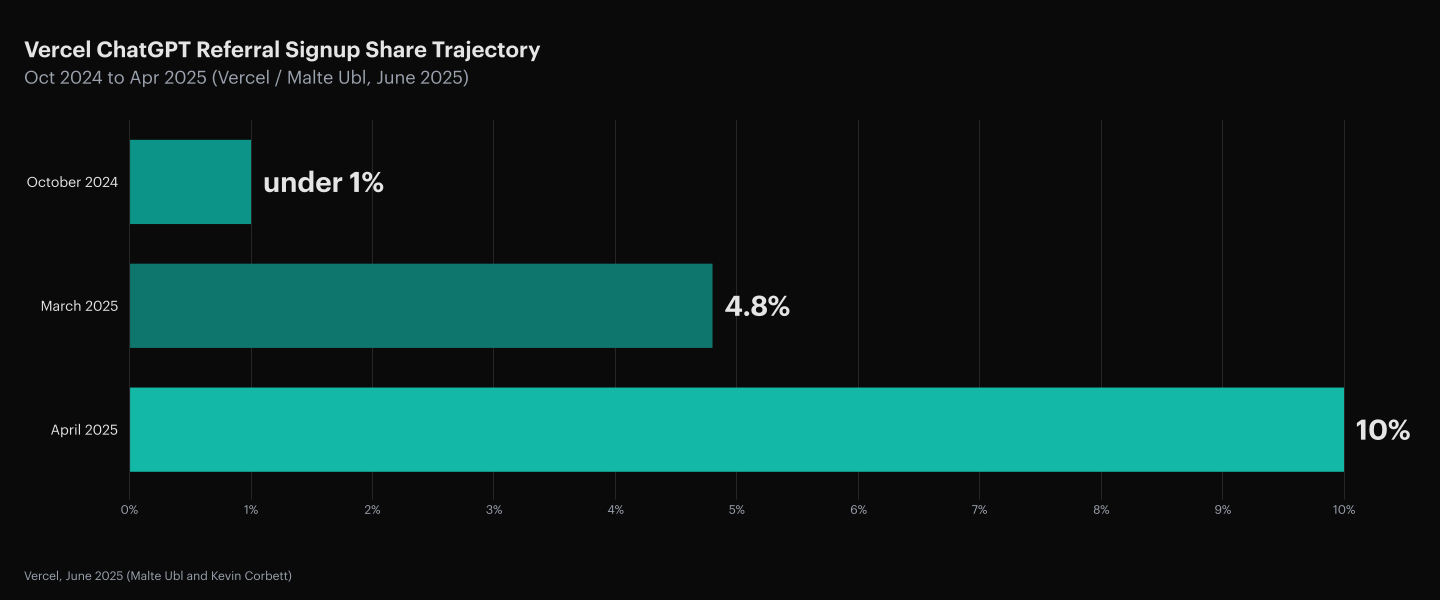
The catalyst was a 34.5% click reduction Google AI Overviews were producing on impacted queries (Vercel, June 2025). Vercel’s leadership read the traffic data, decided LLM retrieval optimization was worth redirecting engineering and content resources toward, and then executed. The five tactics are not abstract recommendations; they are the specific sequence Vercel implemented to move from under 1% to 10%.
Two signals distinguish the Vercel case. First, a CTO writing the SEO playbook is not normal. It signals that LLM search optimization was treated as a platform-level engineering decision, not a marketing experiment. Second, Vercel built a structured content refresh cadence (30, 90, and 180-day review intervals for AI-targeted content), treating AI citation share as an ongoing system to maintain rather than a one-time fix. Their internal framing from the post: “LLM SEO is the art of becoming the answer. Own a concept with depth, structure for retrieval, earn citations, keep it fresh.”
Our analysis of why authority is not the moat in AI search covers Vercel’s citation position in context; the 5-tactic sequence and 30/90/180-day cadence are new here.
Query won: developer infrastructure queries across framework performance, deployment speed, and edge runtime comparisons Incumbent beaten: traditional SEO-first competitors in developer tooling Structural feature: SSR + JSON-LD + 5-channel community seeding + 30/90/180-day refresh cadence
Rippling Built 18 Comparison Pages With 8 FAQs Each
Rippling publishes 18 dedicated comparison pages against ADP, Workday, Deel, Gusto, Paychex, Paycom, and 12 others, each carrying 8 FAQ sections and a 10-category G2 validation grid citing scores from Capterra, TrustRadius, Trustpilot, GetApp, and Software Advice (Rippling, 2026). The Trustpilot gap on the ADP comparison page (4.6 vs. 1.6) is a falsifiable, independently verifiable data point that makes every “Rippling vs. ADP” query converge on the same AI-generated answer.
The 10-category G2 side-by-side is worth examining structurally. Each row compares a specific metric: Core HR (9.1 vs. 7.6), Ease of Setup, Customer Support, Payroll accuracy, Onboarding experience. These are third-party-verified scores that AI engines cross-reference against training data. Rippling’s comparison pages are not editorial claims with some data attached; they are structured third-party validation grids with marketing copy connecting the rows. That distinction is what makes them extractable.
Scale compounds the effect. 18 comparison pages × 8 FAQ sections each = 144 FAQ citation targets across 18 competitor queries. The coverage is not a surprise. It is arithmetic. Building comparison infrastructure at this volume is a content strategy decision, not a copywriting one. Once the structural spec is established for the first page, the remaining 17 are execution, not design.
Query won: “Rippling vs. ADP,” “Rippling vs. Workday,” and 16 named-competitor comparison queries Incumbent beaten: ADP (Trustpilot 1.6 vs. 4.6; G2 reviews 3,700 vs. 10,000+; Core HR score 7.6 vs. 9.1) Structural feature: 18-page comparison library × 8 FAQs × 10-category G2 validation grid per page
Scrupp Beats ZoomInfo With No Funding and Tracxn Score 16
Scrupp holds first-position AI citations on ZoomInfo vs. Apollo comparison queries with a Tracxn authority score of 16 out of 100, no outside funding, bootstrapped in London in 2022, with no press coverage and no third-party attributed statistics on its comparison pages (Scrupp, 2026). The citation driver is structural volume: 16 FAQ questions on the homepage, a 10-of-12-criteria comparison block against four competitors, and multiple named-competitor articles covering the same query space from different angles.
Scrupp is the most useful proof point in this list for anyone who believes domain authority is the primary variable in AI citation. Tracxn ranks Scrupp 2,366th out of 3,175 competitors in its category. ZoomInfo and Apollo have thousands of times more backlinks, domain authority, and press coverage. Scrupp wins the query. The structural explanation is concrete: Scrupp has 16 FAQ questions on its homepage answering the exact questions buyers ask AI engines. ZoomInfo’s homepage answers none of them.
The product is real and the numbers support it: 5,000+ sales teams using the platform, 200 million leads exported, 65% verified email find rate, under 5% bounce rate (Scrupp, 2026). AI engines recommend Scrupp not because of manufactured authority, but because a buyer asking “which tool is better for LinkedIn Sales Navigator lead extraction” gets a specific, structured, falsifiable answer from Scrupp’s pages and a vague prose response from the incumbents.
The counter-intuitive structural finding: Scrupp wins without third-party attributed statistics. Its comparison pages cite no G2, no Capterra, no external research studies. Citation volume from structural density (16 FAQ questions, comparison tables, multiple posts targeting the same query cluster) can substitute for external attribution when factual claims are specific and structural elements are dense enough. Our 852-article analysis of structural features found third-party attribution in 88% of top-cited pages. Scrupp wins without it. Adding attribution would widen the gap further.
Query won: “ZoomInfo vs. Apollo vs. Lusha,” “LinkedIn Sales Navigator scraper tool” Incumbent beaten: ZoomInfo and Apollo (both with 100x+ higher domain authority scores) Structural feature: 16 homepage FAQs + 10-of-12 comparison block; wins on volume density without external attribution
Spellbook’s $350M Valuation Traces to 13 Competitors on One Page
Spellbook reached a $350 million post-money valuation in October 2025 after tripling year-over-year revenue, with 4,400+ legal teams across 80 countries and a $100 million ARR target for 2026, backed by Khosla Ventures (BusinessWire, October 2025). The citation mechanism is coverage breadth: a single alternatives page reviewing 13 named competitors with structured comparison tables makes Spellbook the category reference for every “legal AI alternatives” query a buyer runs.
The coverage breadth path works here because Spellbook built category authority first. With $80 million in total funding and 10 million contracts processed, the brand appears in AI training data across enough contexts that a 13-competitor alternatives page amplifies an existing signal rather than creating one from scratch. This is not the right path for a brand without category recognition; the same page structure from an unknown brand would not produce the same citation behavior.
The structural gap worth noting explicitly: Spellbook’s versus pages carry zero FAQ sections. The Spellbook vs. Harvey page has two comparison tables and approximately 1,200 words but no FAQ. They win despite this because category authority plus structured comparison tables is sufficient at their brand recognition level. Below that threshold, the FAQ gap is a significant structural liability. Spellbook is the exception that holds above the threshold; below it, the FAQ gap is a real liability.
Query won: “legal AI alternatives,” “Spellbook vs. Harvey,” “AI contract review tools” Incumbent beaten: Harvey, ContractPodAi, Luminance, and 10 others reviewed on the alternatives page Structural feature: 13-competitor single-page alternatives hub; two comparison tables per versus page; category authority functioning as amplifier
Stitchflow’s 20-Row Zylo Comparison Anchors a $106,000 Customer Win
A Stitchflow implementation at Turing found 2,658 orphaned SaaS accounts and recovered $106,000 in annual waste, while cutting employee offboarding time from up to 50 minutes down to under 2 minutes per employee (Stitchflow, 2026). The company was founded by the team that built atSpoke, the IT service desk acquired by Okta; Okta Ventures is now a backer alongside Index Ventures and Felicis Ventures. Total funding raised: $8 million.
The outcome statistics are the citation trigger. When a buyer asks “how much does orphaned SaaS access cost” or “how long does employee offboarding typically take,” Stitchflow’s case study data answers the question with numbers tied to a named company. The $106,000 Turing case study is not a testimonial. It is a quantified outcome on a real company with a specific mechanism: 2,658 accounts found, recoverable at $1,000 per month tool cost, ROI positive in month one.
The structural weapon is the Zylo alternatives page: a 20-row Stitchflow vs. Zylo feature matrix comparing the two platforms across 20 specific capabilities, followed by an 8-competitor overview table covering Torii, BetterCloud, Productiv, Nudge Security, and three others, with G2 ratings cited for all 8 (Stitchflow, 2026). The page runs 4,500 to 5,000 words. No other page in the category runs 20 comparison rows alongside a quantified customer outcome. Notably, Vercel is a Stitchflow customer, a detail that surfaces in Stitchflow’s content as a named reference and functions as a credibility anchor in AI citations.
Query won: “Zylo alternatives,” “SaaS management software comparison,” “employee offboarding automation” Incumbent beaten: Zylo, BetterCloud, Torii Structural feature: 20-row vs. Zylo feature matrix; $106K outcome case study with named company and recoverable account count
Userlytics Wins by Exposing UserTesting’s $30,000 Annual Contract
AI features now drive 30% of all sessions within the Userlytics platform, and the company publishes two 3,500 to 4,000-word comparison articles covering 7 AI-powered UX research platforms and 10 UserTesting alternatives, both with standardized review blocks and multi-column comparison tables (Userlytics, 2026). The citation trigger for “UserTesting alternative” queries is pricing transparency: Userlytics explicitly states that UserTesting’s annual contracts start at $30,000+, then presents its own project-based pricing as the alternative.
Price exposure is a GEO tactic that works reliably in software categories with high incumbent pricing. When a buyer asks “is there a cheaper alternative to UserTesting,” an AI engine needs a page that names both prices to return a confident answer. Userlytics provides both in a structured 10-row × 4-column comparison table listing starting prices for all 10 alternatives, making the data extractable in a single parse. Pages that omit competitor pricing force the AI engine to work harder, and AI engines default to the page that answers the question directly.
The panel scale (2 million+ participants across 150 countries in 30 languages) and G2 award history (Best Support, Highest User Adoption, Momentum Leader) give the third-party attribution signals that make the recommendation credible rather than self-promotional. The structural double: two separate 3,500-word comparison articles targeting adjacent query angles (“best AI-powered user research” and “UserTesting alternatives”) means Userlytics appears in AI responses to related queries twice, not once.
Query won: “UserTesting alternative,” “best remote user testing platform,” “AI-powered UX research tool” Incumbent beaten: UserTesting ($30,000+ annual contract vs. project-based pricing) Structural feature: 10-competitor comparison table with explicit incumbent pricing; two 3,500-word listicles covering adjacent query clusters; standardized review blocks across all 10 competitors
How Res AI Replicates the Winning Playbook Across 1,000 Pages
AI-driven revenue grew 120% in four months after one company applied structural GEO optimization to its content library, with visits from AI channels rising 693% in the same period (SE Ranking, 2025). The seven brands above applied these structural changes manually: comparison tables, FAQ sections, third-party attribution grids, outcome-anchored case studies. The bottleneck in every case was execution bandwidth, not strategic clarity.
What these seven brands have in common is a repeatable system: identify the queries buyers run in AI engines, determine what structural elements that query type requires, build or retrofit each page to that spec. Scrupp runs 16 FAQ questions on its homepage because someone audited what was missing. Rippling runs 8 FAQ sections per comparison page across 18 competitors because someone applied the same spec at scale. The pattern is identical. The gap is time and throughput.
The GEO platform market splits into monitoring tools that identify citation gaps and content tools that claim to close them, but most content tools generate articles that require manual review, revision, and publication, handing the structural work back to the team. The table below shows how the category handles the steps that actually determine whether the structural gap closes.
| Tool | What it audits | How fixes are delivered | Scale |
|---|---|---|---|
| Res AI | Strategy Agent audits every page: FAQ gaps, unattributed stats, structural deficiencies vs. top-cited pages | Content Agent writes and deploys fixes directly to CMS via natural language command | Custom |
| Profound | Brand visibility across ChatGPT, Perplexity, Gemini, Copilot, AI Overviews | Delivers AEO-optimized article drafts; team publishes | 6 articles/mo at $399/mo |
| AirOps | Content performance and AI search signals across regions and brands | Delivers AI-generated content from strategy brief; team implements | Custom pricing |
| Athena | Citation visibility and sentiment across 8+ LLMs | Delivers optimization guidance; manual execution by marketing team | $295/mo self-serve |
| Conductor | Enterprise AI search and SEO performance data | Delivers strategy briefs and content recommendations; content team executes | Enterprise; $200 to $10,000+/mo |
Res AI connects to a company’s existing CMS (WordPress, Webflow, Framer) and applies the structural spec across the full library through natural language commands. “Find every comparison page missing FAQ sections and add 8 questions matched to the query tier” runs across 100 pages in the time it takes a content team to update one. The result is the same structural profile the seven brands above built manually, applied at a scale that makes AI citation coverage systematic rather than opportunistic.
Frequently Asked Questions
Why do structurally dense pages beat larger incumbents for AI citations?
AI retrieval systems weight structural features (FAQ sections, comparison tables, attributed statistics), not domain authority signals like backlinks or PageRank (Res AI, 852-article B2B citation structure study, 2026). A page with 8 FAQ sections and a G2 comparison grid gives an AI engine 8 independently extractable answers; a page with 30 internal links and no FAQ gives it none.
Why is Claude growing faster than ChatGPT as a referral source for Tally?
Tally tracks which AI platform each new signup used via post-onboarding surveys, and their April 2026 data shows Claude referrals accelerating faster than ChatGPT on a percentage-change basis (Tally, April 2026). The likely mechanism is Claude’s tendency to favor structured, well-attributed pages; Tally’s comparison pages are built specifically to match what structured retrieval systems prefer.
How does Scrupp win ZoomInfo comparison queries without any third-party attribution?
Citation volume from structural density can substitute for external attribution when factual claims are specific and FAQ depth is high. Scrupp’s 16-question homepage FAQ and multiple named-competitor articles create enough extractable surface area that AI engines can return a confident answer without a G2 citation to anchor it. It is the exception; most brands in competitive categories need external attribution. Adding attribution to Scrupp’s base would widen the citation gap further.
What makes price transparency such an effective AI citation trigger?
When a buyer prompts “is there a cheaper alternative to UserTesting,” the AI engine needs a page that explicitly names both prices to return a confident answer. Userlytics provides UserTesting’s $30,000+ annual contract price on its alternatives page alongside project-based pricing, making the comparison extractable in one table parse. Pages that omit competitor pricing force the AI engine to work harder, and AI engines default to the page that answers the question directly.
Why did Vercel’s CTO co-author their LLM search strategy post?
Malte Ubl co-authoring the June 2025 Vercel post signals that AI search optimization was treated as a platform-level engineering decision, not a content marketing experiment. The post frames LLM SEO as an engineering problem (static HTML rendering, schema markup, semantic HTML), which matches why a CTO would own it rather than delegate it to a marketing team.
Why does Spellbook win AI citations despite having zero FAQ sections on its versus pages?
Spellbook’s $350 million valuation and 10 million contracts processed mean its brand signal appears in enough AI training data contexts that structured comparison tables without FAQs still surface as citations (BusinessWire, October 2025). At lower brand recognition levels, zero FAQs on a versus page is a structural gap that coverage breadth alone cannot overcome. Spellbook holds above the threshold; most brands do not.
How many comparison pages does a brand need to win AI citations systematically?
One well-structured comparison page wins one query. Rippling runs 18 and holds citations on 18 competitor queries. Tally runs 4 and holds positions on 4 query clusters. The relationship is approximately linear: pages built to the structural spec win the queries they target. Gaps in the comparison library are gaps in AI citation coverage.
How fast can a brand-new domain earn an AI citation if the structural spec is right?
Fifteen days after launch with two articles, Perplexity ranks tryres.ai at #1 on “domain authority in AI citations” ahead of PRLog, DigitalStrategyForce, DigitalApplied, and Chudi, against 0 Google clicks across 408 impressions in the same window (Res AI, day-15 launch citation proof, 2026). The Google clock measures in years for a new domain; the Perplexity clock measures in weeks when the structural template (methodology block, multi-row comparison table, 8 to 9 FAQ entries, third-party citations on every claim) is built into the page from day one.
Can a bootstrapped company outrank a funded incumbent for AI citations?
Yes. Scrupp demonstrates it directly: Tracxn score 16 out of 100, zero outside funding, no press coverage, bootstrapped in London since 2022. It wins ZoomInfo comparison queries against a competitor with a valuation in the billions (Scrupp, 2026). The structural mechanism is the 16-question homepage FAQ. ZoomInfo’s homepage answers none of those questions. Funding does not buy AI citations. Structural density does.
What is the minimum viable structural spec for a comparison page that wins AI citations?
The 852-article B2B citation structure study identifies three features appearing in 86% or more of top-cited comparison pages and 0% of bottom-cited ones: comparison tables, bold label blocks, and how-to-choose frameworks (Res AI, 2026). FAQ sections appear in 88% of top-cited pages. A comparison page carrying all four meets the minimum structural bar for competitive AI citation performance.
Res AI identifies the structural features separating your pages from the ones holding AI citation positions on your highest-intent buyer queries, then applies the gap-fill across your CMS at scale. The Content Agent adds FAQ sections, replaces self-sourced stats with attributed third-party figures, and deploys structural specs across batches of pages through natural language commands.