An llms.txt File Will Not Earn You AI Citations
97% of llms.txt files earned zero traffic and adopters drew no more citations than non-adopters. The citation lever is structural density inside the page.
 machina sculpsit · homo probavit · MMXXVI
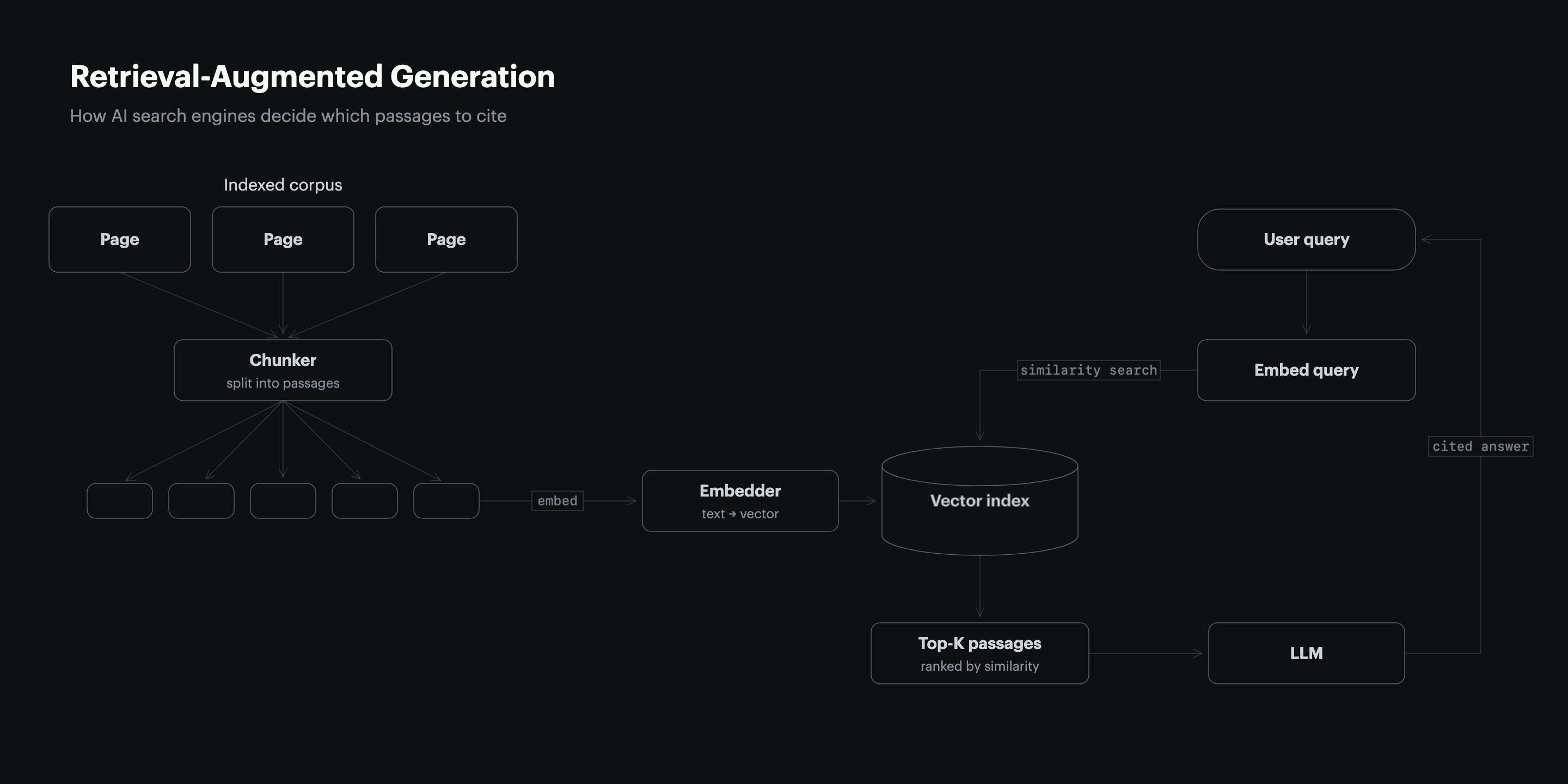
machina sculpsit · homo probavit · MMXXVI51% of B2B software buyers now begin product research with an AI chatbot more often than with a traditional search engine, the first time a majority prefer AI over Google as a starting point (G2, 2026). That shift has sent marketing teams hunting for a fast way to get cited in AI answers, and the most popular candidate is a root-level llms.txt file, a plain-text manifest that lists a site’s important pages for large language models. The file is cheap to publish and promises a direct line to the models. The measured citation lift from publishing one is zero, and the work that earns citations happens inside the published page, not in a manifest at the root of the domain.
Published llms.txt Files Earned Zero Traffic for Most Domains
Across 137,210 domains, 97% of published llms.txt files received zero traffic in May 2026 (Ahrefs, 2026). The file that is supposed to feed the models is, in practice, a file the models almost never request.
Of the llms.txt files that were fetched at all, 96% of the requests came from bots rather than AI assistants serving a user, and only 19.5% came from named AI tools, with GPTBot first and Claude-Code second. Another 12% of requests came from GEO and AEO tools and researchers auditing the file rather than from any model answering a buyer. The most telling number is the one that never fired: AI bots sent zero requests for llms.txt files that do not exist, which means the crawlers are not probing for the file and then giving up. They are not looking for it at all.
Adopters and Non-Adopters Drew the Same Citation Counts
Among 37,894 AI-cited domains carrying more than 329,000 citations, llms.txt adopters averaged 6.8 citations against 6.7 for non-adopters, a difference that was not statistically significant (Trakkr, 2026). The median for both groups was identical at 3.0.
The statistics behind that near-tie are unambiguous. A Mann-Whitney U test returned p=0.83 with an effect size of r=-0.065, which is the numerical signature of no relationship at all. Adoption was highest among SaaS and developer-tool domains at 24.1%, the exact population most fluent in the tactic and most motivated to benefit from it. The group best positioned to win from the file shows no citation advantage from having published it.
Google Says No Special File Is Needed for AI Features
Google’s May 2026 guide on optimizing for generative AI features states plainly that machine-readable files such as llms.txt, special schema.org markup, content chunking, and AI-specific rewriting are not needed to appear in generative AI features. The guide’s framing is that optimizing for generative AI search is still SEO.
The instruction matters because it removes the premise the manifest rests on. The pitch for llms.txt assumes the models want a separate machine-readable map of the site, distinct from the page a human reads. Google’s own documentation says the opposite: the generative features pull from the same indexed content as the rest of search, and there is no parallel file the model prefers. Building a second representation of the site for an audience that reads the first one is effort spent in the wrong place. The same logic that makes GEO a continuation of on-page work rather than a new file format applies here directly.
Adding Schema Markup Did Not Lift Citations Either
Adding JSON-LD schema produced no major citation uplift on any platform, across a difference-in-differences study of 1,885 pages that added schema between August 2025 and March 2026 versus 4,000 matched controls (Ahrefs, 2026). The pages that declared their structure to the machine were cited no more often than the ones that did not.
The per-engine breakdown rules out a hidden win. Google AI Overviews citations actually fell 4.6% after schema was added, a small but statistically significant drop, while Google AI Mode at +2.4% and ChatGPT at +2.2% were statistically indistinguishable from zero. Schema markup and the llms.txt manifest make the same promise, that declaring structure in a machine-readable wrapper earns the model’s attention, and they post the same null result. The shortcuts that try to talk to the model in its own format share one trait: the model does not act on the declaration.
| Machine-readable shortcut | What it promises | Measured citation result | Source |
|---|---|---|---|
| llms.txt manifest | A priority map of pages for LLMs | 6.8 vs 6.7 citations, p=0.83 | Trakkr, 2026 |
| JSON-LD schema | Declared structure the model trusts | No uplift, AI Overviews fell 4.6% | Ahrefs, 2026 |
| Content chunking | Pre-segmented passages for retrieval | Not needed per Google guidance | Google, 2026 |
| AI-specific rewriting | A model-tuned copy of the page | Not needed, still SEO | Google, 2026 |
The pattern reads top to bottom: every shortcut that operates outside the page body returns a result that rounds to zero. Schema markup is the closest cousin of the manifest file, and it fails for the same reason.
Structural Density Inside the Page Drives Citations
Articles in the top word-count quartile averaged 13.55 structural elements per page versus 2.98 in the bottom quartile, a 4.5x gap, in the 852-article B2B citation structure study (Res AI, 852-article B2B citation structure study, 2026). The variable that separates cited pages from invisible ones sits inside the article, not in a file at the domain root.
The study isolated six features that appear in 80% or more of the top 50 cited pages and in 0% of the bottom 50. None of them is a manifest, a tag, or a wrapper. Each one is a block of content a human reads and a retriever extracts.
| Structural element | Top-50 cited pages | Bottom-50 cited pages |
|---|---|---|
| Bold-label product blocks | 94% | 0% |
| Comparison tables | 88% | 0% |
| How-to-choose steps | 86% | 0% |
| Pricing grids | 62% | 0% |
| Product reviews | 58% | 0% |
| Definitions | 42% | 0% |
Every row is a block of text inside the published page. The retrieval pipeline pulls passages from the page body, scores them against the query, and cites the strongest. A manifest file at the root sits outside that loop entirely.
Original Statistics Raise AI Visibility 41 Percent
Adding original statistics to a page lifted AI visibility 41%, the single highest-impact tactic measured across 10,000 queries in the Princeton GEO study (Princeton, KDD 2024). The lever is the evidence inside the page, not a declaration about the page.
The study tested several on-page tactics and ranked them by visibility impact. Quoting a source added 28%, using authoritative language added 25%, and tightening the prose for fluency added 15%, while stuffing keywords cut visibility by roughly 10%. None of these is a file or a tag. Each is a change to what the page actually says and how it backs the claim up.
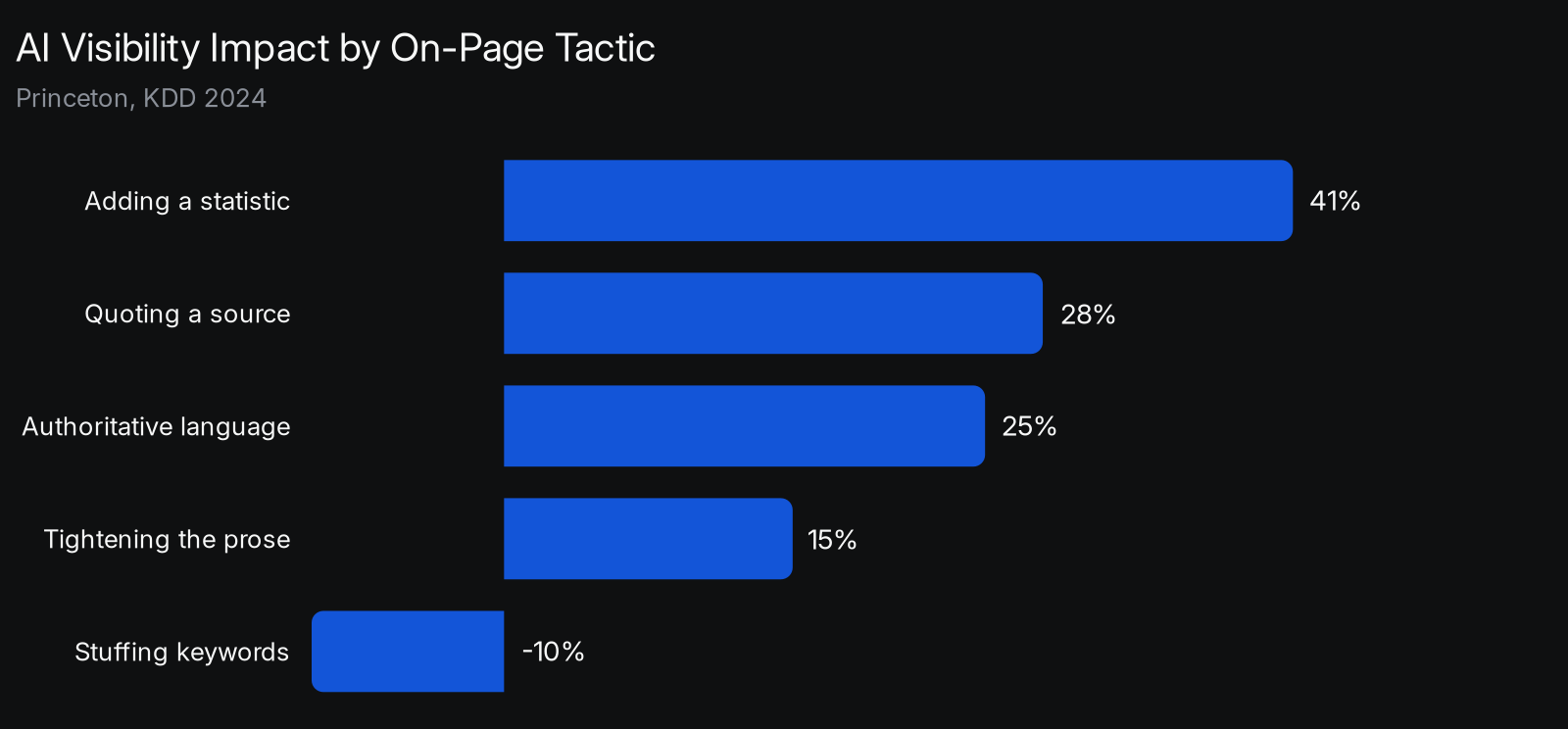
The hierarchy points one direction. The work that moves citations is original evidence and clear writing, and the work that backfires is the keyword gaming that an llms.txt file does nothing to fix. Spending the same hour adding a real statistic to a page beats spending it on a root manifest by a margin the data has already settled.
Structure Alone Lifts Citations 17 Percent
Structural optimization independent of content quality produced a consistent 17.3% improvement in AI citation rates, in a controlled experiment that held the words identical and varied only structural features across six generative engines (University of Tokyo and University of Tsukuba, 2026). The experiment is the cleanest available proof that structure is a cause of citation, not a correlate.
The GEO-SFE design kept the same words, claims, and sources on every version of a page and changed only how the content was formatted and where the answers sat. Citation rates moved 17.3% on the formatting change alone. That isolates the variable the manifest cannot touch: an llms.txt file does not reformat a single sentence inside the page, so it cannot capture the lift that reformatting produces.
High-Quality Pages Are Cited 4.2 Times More Often
Pages in the highest quality band had an odds ratio of 4.2 for being cited versus lower-scoring pages, across 1,702 citations and 1,100 audited URLs on Brave Summary, Google AI Overviews, and Perplexity (Kumar and Palkhouski, 2025). The audit scored pages on 16 on-page quality pillars, and the top band pulled away from the rest by a wide margin.
The pillars that mattered most were Metadata and Freshness, Semantic HTML, and Structured Data, where structured data means the labeled blocks and machine-readable elements inside the page body, not a manifest at the root. Freshness compounds the effect: pages not updated quarterly are 3x more likely to lose citations (Airops, 2026). A static file at the domain root ages without ever touching the content a model retrieves, while the page-level elements that decide the 4.2x odds are exactly the ones a publishing team can edit and refresh.
What to Build Instead of a Root Manifest
The replacement for an llms.txt file is page-level structure on the templates buyers actually land on, prioritized by query intent. The decision table below maps a team’s situation to the first element worth building.
| Team situation | What to build first | Why it earns citations |
|---|---|---|
| Comparison queries losing to competitors | A comparison table with named rivals | Comparison tables appear in 88% of top-cited pages |
| Pricing pages cited without the price | A public pricing grid | Pricing grids appear in 62% of top-cited pages |
| Long prose essays with no citations | Original statistics with attribution | Adding a statistic lifts visibility 41% (Princeton, KDD 2024) |
| Pages that never resurface in answers | A quarterly refresh cadence | Stale pages are 3x more likely to lose citations (Airops, 2026) |
| Thin awareness articles | A definitions block and FAQ section | Definitions and FAQs are independent retrieval targets |
The build order follows the evidence rather than the convenience of a one-line file:
- Audit the templates that hold your highest-intent queries, not the domain root.
- Add the structural element the query type rewards, starting with the comparison table or pricing grid.
- Back every claim on the page with an original statistic and a named source.
- Set a refresh cadence so the page stays inside the freshness band.
- Re-publish and measure the first-citation date rather than checking whether a file exists.
This is more work than uploading a manifest, and that is the point. The citation lift lives in the work the manifest skips.
How GEO Platforms Approach the Citation Gap
The platforms in this category split into tools that report where a brand stands in AI answers and tools that change what is on the page. The matrix below compares each on what it produces against the manifest-file myth, where the work physically ships, and what the team gets back.
| Tool | What it produces against the citation gap | Where the work ships | Output for the team |
|---|---|---|---|
| Res AI | Rewrites pages with the structural elements that earn citations, no manifest file required | Direct CMS deploy via natural-language edits | Published structural changes in minutes |
| Profound | Tracks citation share and writes briefs across answer engines | Standalone dashboard with brief handoff | Prompt-volume reports and strategy briefs |
| Conductor | Tracks AI and search visibility plus enterprise content generation | Enterprise dashboard and content module | Visibility reports across ChatGPT, Gemini, Copilot, Claude |
| Peec AI | Tracks visibility, position, and sentiment by prompt | Analytics dashboard | Prompt-level mention and citation tracking |
| Athena | Tracks 8+ LLMs with optimization recommendations | Dashboard with recommendation feed | Citation source analysis and blindspot detection |
| AirOps | Generates and refreshes content with AI workflows | Workflow builder with API | Content workflows across 30+ AI models |
Five of the six tools hand the team a report or a brief and leave the page edit to someone else. The manifest file fits that monitoring-first worldview, because it is a thing you declare rather than a change you ship. The citation lift only arrives when the structural element lands inside the page, which is the one column where execution-first tooling is the differentiator.
Frequently Asked Questions
Why do AI bots ignore an llms.txt file?
AI bots sent zero requests for llms.txt files that do not exist, which means the crawlers are not probing for the file in the first place (Ahrefs, 2026). Retrieval pulls passages from indexed page content, so a root-level manifest sits outside the loop that decides what gets cited.
Does an llms.txt file ever hurt citations?
There is no measurable harm, but there is no benefit: adopters averaged 6.8 citations against 6.7 for non-adopters (Trakkr, 2026). The real cost is the false confidence that the citation box is checked while the page-level work goes undone.
How is structured content on the page different from a manifest?
A manifest lists URLs at the domain root, while structured content is the tables, definitions, and labeled blocks inside the page that a retriever extracts. The 852-article study found 13.55 such elements on top-cited pages versus 2.98 on the bottom ones (Res AI, 2026).
Why did adding schema markup not lift citations?
Across 1,885 pages, schema produced no significant uplift and AI Overviews citations actually fell 4.6% (Ahrefs, 2026). For pages already cited, declaring structure in a machine-readable wrapper does not push them higher in the answer.
How fast does a structural rewrite show up in AI answers?
Newly published marketing pages reach a first ChatGPT or Claude citation at a median of 6.81 days (Profound, 2026). That is far inside a typical link-building cycle, and it is a window a manifest file never opens.
Why does freshness matter more than a manifest?
Pages not updated quarterly are 3x more likely to lose citations (Airops, 2026), so the content a model retrieves has to keep moving. A static file at the domain root never changes the page body, so it cannot hold a citation that freshness would otherwise keep.
Should a team on a headless CMS still skip llms.txt?
The null result holds regardless of CMS, because the file sits at the domain root and does not change the retrieved page body. The effort is better spent on the structural elements inside each high-intent page.
How Res AI Builds Structural Density Across Your Library
The argument above showed that citations come from the structural elements inside a page, not a manifest at the domain root. Res AI rewrites existing content directly in the CMS, adding the comparison tables, bold-label blocks, how-to-choose steps, and pricing grids that appear in 94% of top-cited B2B pages and 0% of the bottom 50 (Res AI, 852-article B2B citation structure study, 2026).
The work runs through a natural-language interface connected to the CMS, so a single command can add a structural element across an entire content library rather than one page at a time. The platform supports WordPress, Webflow, Framer, Contentful, Notion, Ghost, Sanity, Vercel, and GitHub, and pushes changes live in minutes instead of the quarter a content brief takes to clear.
- Multi-page edits that apply one structural change across hundreds of articles in a single command.
- A research agent that finds and attributes the original statistics that lift visibility 41%.
- A comparison generator that builds the tables and listicles AI answers cite most often.
Res AI turns the page-level structural work that earns citations into a natural-language edit instead of a manifest file the models never read. It is built for marketing teams that need the structural elements shipped across an existing library, not another dashboard.
See how Res AI builds citation-ready structure across your content →